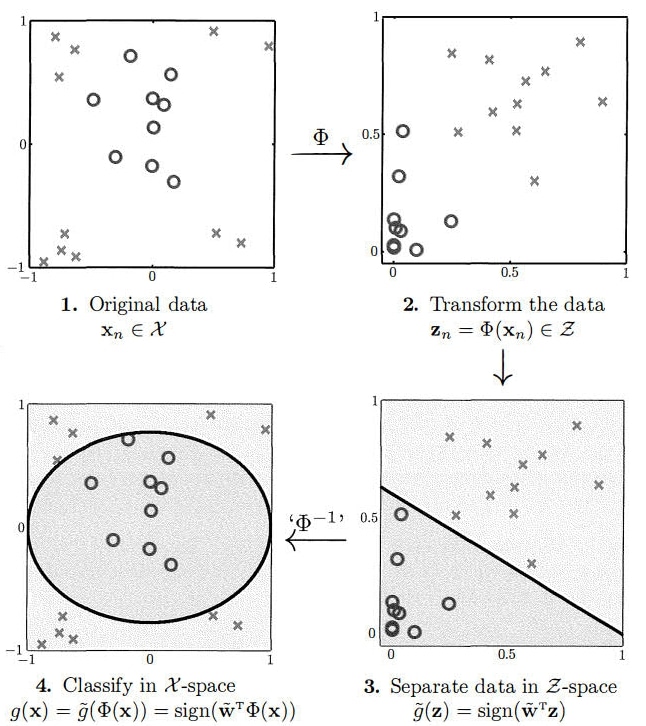
Curso dado no Instituto Matemático da UFAL no semestre de inverno de
2019. Introduz
às aplicações,
às implementações e
à teoria
dos algoritmos de aprendizado de máquina.
Introdução
Para quê estudar o Aprendizado de Máquina? A resposta
esmagadora do guru Andrew Ng:
“I hope we can build an AI-powered society that gives everyone
affordable healthcare, provides every child a personalized education,
makes inexpensive self-driving cars available to all, and provides
meaningful work for every man and woman.”
Traduzido para português:
“Espero que possamos criar uma sociedade baseada na inteligência
artificial, que
oferece um plano de saúde acessível a todo mundo,
proporciona uma educação personalizada a cada criança,
disponibiliza carros auto-conduzidos baratos a todos, e
um trabalho significativo com sentido a cada homem e mulher.”
Amem. Vamos levar o Brasil para frente!
Objetivo do Curso
Este curso inicia o leigo aos métodos básicos do aprendizado de
máquina. Tradicionalmente, foram introduzidas regras ao computador
para ele calcular as consequências. No aprendizado de máquina,
são introduzidos dados ao computador para ele calcular as regras,
detectar as regularidades neles (e, em seguida, calcular as
consequências destas regras).
Com o advento de cada vez maiores volumes de dados e maior potência
computacional, o aprendizado de máquina torna-se cada vez mais
proveitoso. Por exemplo,
na medicina: a partir de um conjunto de dados de saúde com os
diagnósticos por especialistas, aprender a diagnosticar.
na mineração de dados, o uso de aprendizado de máquina
para detectar estruturas estatísticas lucrativas (em bancos de dados
relacionais). Notavelmente, para antecipar
os interesses de um usuário de um portal on-line a partir daqueles
nas visitas anteriores;
em particular, as futuras compras dos clientes de um comércio
on-line a partir das anteriores.
Resumo
O aprendizado de máquina faz cada vez mais sucesso na
resolução de problemas computacionais até há pouco acreditados
irresolúveis: Talvez o mais espetacular seja a derrota fulminante do
melhor jogador de Go mundial por AlphaGo, uma inteligência artificial
baseada no aprendizado de máquina. Até então, os computadores chegavam
nem sequer perto aos mestres. Como exemplo protótipo e primeira
aplicação, olhamos a classificação de e-mails em Spam (= lixo) e Ham (=
não Spam) pelo aprendizado a partir dum conjunto exemplar de e-mails
sorteados. Este algoritmo de aprendizado de máquina, baseando-se
unicamente na frequência de palavras-chave lixosas no e-mail, revelou-se
mais eficiente do que todos os outros até então criados.
Os métodos básicos por trás do aprendizado de máquina são
principalmente geométricos: Dado um conjunto de pontos, buscam-se (por
exemplo, nos métodos da regressão linear/logística, da
Support vetor Machine ou do K-means) as melhores (em
um sentido preciso) retas, hiperplanos (em dimensão maior) ou
compartimentos para separá-los.
Além da solução deste problema teórico, geométrico, há os problemas
práticos:
o da dificuldade computacional, e
o da significância (como modelação da realidade).
Para reduzir a dificuldade computacional há, por exemplo, o método da
análise de componentes principais (para reduzir o número de
parâmetros com perda informacional mínima). Como problema de
significância, surge o do Sobre-Ajuste, quer dizer, que o
resultado só se aplica aos dados usados, mas em geral não, e o
Método de Regularização ajuda mitigá-lo.
Cronograma
Estudamos os fundamentos do curso Machine Learning por Andrew Ng
disponível no coursera.org pelo livro Abu-Mostafa,
Magdon-Ismail, e Lin (2012) disponível gratuitamente online no
endereço Learning from
Data.
Começamos com a parte teórica:
Explicamos e formalizamos o que é um problema de aprendizado
(supervisionado).
Formalizamos a noção de aprendizagem pelo PAC (=
Provavelmente Aproximadamente Correto). O PAC dá em
particular uma explicação matemática ao problema recorrente do
Sobre-Ajuste, quando as conclusões se aplicam só aos dados
analisados, mas não revelam nada geral.
Mostramos pela dimensão de Vapnik-Chervonenkis que uma grande
classe de problemas é apreensível.
Concluímos com a parte prática:
Os métodos lineares:
O método do Perceptron em uma variável e em várias
variáveis. Geometricamente, busca-se um hiperplano que separa dois
conjuntos de pontos.
O método da Regressão Linear, geometricamente, para dados
pontos busca-se uma reta que os aproxime o melhor possível.
O método da Regressão Logística que mede a probabilidade de
uma propriedade; Por exemplo, se um e-mail é spam ou não.
O Método do Máximo Declive (estocástico)
(Gradient Descent) para encontrar extremos de funções (em
várias variáveis); por exemplo, minimizar as distâncias nos métodos
lineares acima.
O método da Máquina de Vetores de Suporte
(Support vetor Machine), como extensão não-linear
(kernelization) do Perceptron:
Geometricamente, busca-se um hiperplano que separa pontos em duas
classes. Em comparação à Regressão Logística computacionalmente
preferível quando há poucos parâmetros, quer dizer, a dimensão é
pequena.
Redes Neurais como iteração da Regressão Logística em várias
variáveis;
os seus modelos, e
o algoritmo da Retropropagação de Erro, um método de máximo declive
que reajusta os pesos dos neurônios conforme a uma regra de correção de
erro.
O método das K-médias (K-means) cuja saída
é finita. Geometricamente, busca-se uma divisão de pontos em
compartimentos tal que ela minimize as distâncias entre os pontos em
cada compartimento.
O método da Análise da Componente Principal
(análise de componentes principais) para projetar um
conjunto de pontos a um espaço de dimensão menor sem perda de informação
quanto à sua classificação.
Otimizar
Para otimizar, isto é, encontrar um ponto em que uma função (de erro)
tem o seu valor mínimo, usaremos
uma aproximação iterativa, um método de ensaio e erro direcionado,
como no Perceptron,
a projeção de um vetor a um (hiper)plano (onde o vetor de saída é o
vetor do (hiper)plano que é mais próximo do vetor de entrada), e
a computação de um ponto em que a derivada
de
é zero.
Os métodos numéricos (iterativos) para calcular esta projeção ou o
ponto em que a derivada é zero serão só superficialmente explicadas.
Aspectos
Matemáticos
Recapitulamos noções básicas
da Álgebra Linear para tratar problemas multidimensionais como o da
regressão linear em várias variáveis,
da análise multidimensional para encontrar pontos (localmente)
máximos de funções em várias variáveis.
Esta secção explica a linguagem matemática básica, conjuntos e
funções. Como as notações usada na matemática acadêmica diferem em uns
pontos das do ensino escolar, repitamos as mais comuns:
Conjuntos
A noção fundamental da matemática é a de um conjunto;
segundo os dicionários Aurélio, Houaiss ou Michaelis:
qualquer coleção de seres matemáticos,
qualquer reunião de objetos, determinados e diferenciáveis, quer
esses objetos pertençam à realidade exterior, quer sejam objetos do
pensamento, ou
qualquer reunião das partes que constituem um todo.
Esta coleção de seres matemáticos é denotada por
.
Se um ser matemático
pertence ao conjunto
,
dizemos que
é em
e escrevemos
ou
.
Por exemplo, o conjunto
dos números naturais
é denotado por
.
dos números inteiros
é denotado por
,
dos números racionais
é denotado por
;
por exemplo,
é nele , e
dos números reais
para
,
,
,
,
em
,
,
,
é denotado por
;
por exemplo,
é nele.
Podemos comparar dois conjuntos
e
:
denote
que
contém (ou inclui)
,
e
denote
que
é contido (ou incluso)
.
Podemos formar um novo conjunto a partir de dois conjuntos
e
:
denote
a união de
e
,
o conjunto dos elementos que pertencem a
ou
,
denote
a intersecção de
e
,
o conjunto dos elementos que pertencem a
e
;
se
,
então denote
a diferença entre
e
,
o conjunto dos elementos que pertencem a
mas não a
.
Por exemplo, os números irracionais são todos os números
reais que não são racionais, isto é, que pertencem ao
.
Denote
o seu produto cujos elementos são
para
em
e
em
,
isto é,
Se
,
escrevemos
em vez de
,
e
em vez de
,
e assim por diante. Por exemplo,
é o plano (euclidiano), e
é o espaço.
Funções
Fórmula
Uma função descreve a dependência entre duas quantidades. No
ensino escolar, é usualmente denotada por uma equação
onde na expressão figuram
operações aritméticas
,
,
,
…
sobre números reais, constantes, funções algébricas como
e funções especiais como
,
,
,
…
Por exemplo:
A distância
percorrida por um objeto na queda livre depende do tempo da queda
:
vale
onde
é a constante da aceleração gravitacional da terra.
A forca de atração
entre duas massas
e
depende de
,
e a distância
entre elas: Pela lei gravitacional de Newton
onde
é a constante de gravidade universal de Newton.
Porém, existem outras dependências, por exemplo:
O preço de uma entrada ao teatro de fantoches depende do número da
fila do assento: Esta dependência descreve-se por uma tabela de preços,
dando o número da fila
,
,
,
… e o preço correspondente de
Centavos,
Centavos,
Centavos, …
Definição. Uma função
é uma regra que associa a cada elemento
de um conjunto
exatamente um elemento
de um conjunto
.
Esta associação é simbolicamente expressa por
.
Refiramo-nos
a
como variável (independente) ou argumento,
a
como variável dependente ou valor (da função),
a
como domínio da função, e
a
como contra-domínio da função.
A
de
é o conjunto de todos os valores de
,
Por exemplo,
e
para a função constante
.
O contra-domínio contém a imagem, mas não necessariamente coincide com
ela,
Usualmente, vemos funções com
e
,
isto é, funções reais; chamamo-nas muitas vezes simplesmente de
funções. Usualmente as letras
denotem números reais; as letras
denotem números naturais (usados para enumerações). Nos nossos
exemplos:
Aqui (a magnitude) de
em
e
.
Tem-se
e
.
Aqui (a magnitude) de
em
e
em
.
Tem-se
e
.
Aqui
e
.
Funções reais aparecem em diversas formas: além de
uma equação,
obtemos pela substituição da variável por um número real como
,
,
,
,
…
uma tabela de valores
e
dado pela avaliação do lado direito da igualdade
,
e
um gráfico
pela marcação dos pontos
no plano que são dados pelos valores da tabela, e
pela conexão destes pontos.
Em mais detalhes:
Na forma de uma equação como nos exemplos acima:
,
por exemplo,
Para facilitar, fazemos o convênio seguinte: Se escrevemos apenas a
regra de associação, por exemplo,
ou
,
então o domínio é o subconjunto máximo de
para que esta regra seja definida (quer dizer, faça sentido). Por
exemplo, nestes exemplos,
e
.
Na forma de uma tabela de valores, por exemplo: Um experimento
mede a tensão
de um resistor em dependência da corrente
.
A tabela tem as entradas
e
. Aqui
(e
).
(Gostaríamos de extrapolar esta função, isto é, estender o seu domínio a
;
a este fim, parece provável que
com
.)
A equação funcional
associa a cada valor
um único valor
,
em símbolos,
.
Um tal par de valores
pode ser interpretado como ponto
no plano cartesiano. Para cada par de valores
obtemos exatamente um ponto. Dado um ponto
,
os números reais
e
são chamados das coordenadas (cartesianas). O conjunto de todos
os pontos
forma a curva da função (ou gráfico), que ilustra o
percurso da função
.
(Por exemplo, a parábola
ou uma função afim
.)
Para desenhar a curva:
Enche uma tabela de valores para uns argumentos
,
,
…
Desenha os pontos dados nela, e
Conecta-os para obter o percurso da curva da função.
Coordenadas Cartesianas de um ponto nos
eixos
e
De vez em quando, para destacar que um objeto, por exemplo, uma
função
,
depende de outro objeto, por exemplo, de um conjunto
ou uma ênupla
,
escrevemos
ou
respetivamente
ou
em vez de
.
Aplicação
No ensino acadêmico, uma função ou aplicação é
denotada por
para os dois conjuntos,
o domínio
,
e
o contra-domínio
de
dizemos que manda ou envia cada argumento
em
a um único valor
em
.
Lê-se que
é uma função de
a
,
ou tem argumentos em
e valores em
.
No contexto informático, pensamos de
como um algoritmo, e referimo-nos a
e
como entrada e saída.
Uma função manda ou envia cada argumento
em
a um único valor
em
(ou associa a cada
um único
).
Escrevemos
e denotemos este valor
por
.
Frequentemente,
ou
e
ou
.
Por exemplo, a função
dada por
manda
em
a
em
.
Função e aplicação são sinónimos. Contudo, a
conotação é outra: Se os objetas do domínio são, por exeplo, números
inteiros, conjuntos, então aplicação é mais comum, enquanto
função é principalmente usada quando o domínio consiste de (ênuplas de)
números reais.
Formar Novas
Funções
Composição
A partir de duas funções
e
(sobre quaisquer domínios e imagens) pode ser obtida outra por
concatenação; a função composta ou a
composição
,
dado que a imagem de
é contida no domínio de
,
isto é,
.
É definida por
simbolicamente, para obter
,
substituímos
em
por
.
Se temos duas funções,
isto é, tais que os valores de
são argumentos de
,
a sua composição é definida por
isto é, a saída de
é a entrada de
,
e denotada por
Inversão de funções
Por definição, uma função
associa a cada argumento
exatamente um valor
.
Frequentemente surge o problema inverso: Dado um valor
,
determina o seu argumento
sob
,
isto é, tal que
.
Se uma função
é injetora, isto é,
implica
,
isto é, a argumentos diferentes são associados valores diferentes, então
a cada valor
é associado um único argumento
.
A função
obtida pela associação inequívoca inversa
,
ou
é a ou o de
e denotada por
.
Ora,
é a variável e
a variável . Em fórmulas, a função inversa
é obtida pela permutação das duas variáveis
e
na equação
.
Matematicamente, a função
tem o inverso
,
se
e
.
Por exemplo, sobre
vale
para
,
e
para
e
.
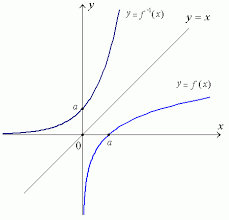
Para desenhar a função inversa, poderíamos permutar as designações
dos dois eixos. Porém, isto comumente não se faz. Porém, se o domínio e
a imagem coincidem, o gráfico da função inversa
é o espelhamento do gráfico da função invertida
na diagonal dos pontos cuja coordenada
é igual à coordenada
.
A função inversa
Exemplos. Olhemos uns exemplos de funções
invertíveis. Observamos em particular que a invertibilidade depende do
domínio: Quanto menor o domínio, tanto mais provável que a função seja
invertível.
A parábola
não é invertível sobre
,
mas só sobre
e
(pela radiciação quadrática).
A função
cresce de modo estritamente monótono, em particular, é invertível.
O seno (que mede o comprimento do cateto oposto no círculo unitário)
cresce de modo estritamente monótono no intervalo
;
logo tem um inverso, o neste intervalo.
a exponencial
é invertível pelo logaritmo
.
Resumimos:
Toda função estritamente monótona (crescente ou decrescente) é
invertível.
Na inversão o domínio e imagem trocam os papéis.
Se o domínio e imagem coincidem, obtemos o gráfico da função inversa
pelo espelhamento do gráfico da função na diagonal
.
Algarismos
Um número real no dia-a-dia é escrito em notação decimal
com
,
,
,
,
, em
.
Isto é, é como soma em potências de
e com algarismos
,
…,
.
Por exemplo,
Em vez da base decimal
,
existem outras. As mais comuns na informática são
a base binária
com os algarismos
e
,
e
a base hexadecimal
com os algarismos
e
,
,
,
,
e
(que correspondem a
,
,
,
,
e
).
Isto é,
no conta-quilómetro binário, o último algarismo retorna à posição
inicial após dois quilómetros, o penúltimo após
quilómetros, e assim por diante,
no conta-quilómetro hexadecimal, o último algarismo retorna à
posição inicial após
quilómetros, o penúltimo após
quilómetros, e assim por diante.
Por exemplo,
e
1 O que é um problema de
aprendizado?
Tradicionalmente, foram introduzidas regras ao computador para ele
calcular as consequências.
regras
computador
resultados
No aprendizado de máquina, são introduzidos dados ao
computador para ele calcular as regras, detectar as regularidades neles
(e, em seguida, calcular as consequências destas regras).
dados
computador
regras
(
computador
resultados)
Com o advento de cada vez maiores volumes de dados e maior potência
computacional, o aprendizado de máquina torna-se cada vez mais
proveitoso.
1.1 Categorias de Aprendizado
Primeiro destacamos a diferença entre aprendizado e
especificação para resolver um problema de
classificação. Com efeito, o aprendizado leva a especificação:
Na especificação, são introduzidas regras ao computador para
ele calcular as consequências. No aprendizado de máquina, são
introduzidos dados ao computador para ele especificar as regras (e, em
seguida, calcular as consequências das regras).
Recordemo-nos
dados
computador
regras
computador
resultados
Enquanto
o computador à esquerda aprende as regras, especifica-as,
o computador à direita aplica-as para calcular os resultados.
Exemplo: para distinguir entre valores de moedas
pelos seus pesos e tamanhos, usamos
a especificação se contatamos a cada da moeda e
classificamos as moedas por estas medidas com uma certa margem de erro,
e
o aprendizado se derivamos estas medidas com uma certa
margem de erro a partir de um grande conjunto de moedas.
Concluímos:
Figura 1.1: Agrupamento de moedas por peso e
tamanho
Se os círculos foram desenhados antes dos pontos, trata-se
de especificação. Se os círculos foram desenhados
depois dos pontos, trata-se de aprendizado.
O termo que usamos daqui para diante
para os dados a partir de que aprenderemos será a amostra
ou os exemplos.
Pensamos
de cada exemplo como uma entrada, e
do nosso resultado de aprendizado (tipicamente uma classificação)
como saída.
Aprendizado com
Supervisionamento
No aprendizado com supervisionamento, os exemplos são
classificados. Isto é, temos pares
Por exemplo, duas pastas de e-mails, a
primeira do tipo spam, a outra do tipo
ham.
Aprendizado por Reforço
No aprendizado por reforço, os exemplos da amostra são
parcialmente avaliados. Isto é, temos pares
Destacamos que, dada uma entrada
,
não necessariamente todos os pares
para todas as possíveis saídas
são contidos na amostra.
Exploração
Quer dizer, não sabemos necessariamente quão boas outras saídas
poderiam ter sido. Por exemplo, ao aprender um jogo de tabuleiro, dado
uma configuração
do tabuleiro,
será o lance e a sua avaliação a probabilidade de ganhar o jogo.
A avaliação
No aprendizado por reforço, a avaliação é uma função na entrada e
saída. Por exemplo,
no jogo Xadrez, a função poderia avaliar a configuração do tabuleiro
pelo número de peças de cada um,
pela a sua centralidade e agilidade;
no jogo Go, a função poderia contar
as pedras e
as casas controladas por elas;
no jogo Gamão, simplesmente avaliar uma configuração como
neutra se o partido é indeciso,
positiva
(),
se o partido é ganhado, e
negativa
(),
se o partido é perdido.
Aprendizado sem
Supervisionamento
No aprendizado sem supervisionamento, os exemplos são
inclassificados.
Isto é, o otimizador
Precisa de criar as possíveis saídas, ou os rótulos, e
depois classifica.
O exemplo principal é o clustering, ou agrupamento.
Por exemplo, mesmo sem rótulos, as moedas podem ser agrupadas pelos seus
pesos e tamanhos, vide Figura 1.1
1.2 Exemplos de
Aprendizado Supervisionado
Por exemplo,
na medicina: Aprender a diagnosticar a partir de
dados sobre à saúde dos pacientes e
os seus diagnósticos.
na identificação de conteúdo: Decidir se um e-mail é
Spam (= lixo) (ou Ham [= não Spam]) a partir
de duas pastas de e-mails,
uma do tipo Spam e
a outra do tipo Ham.
O otimizador de aprendizado a ser apresentado, que se baseia
unicamente na frequência de palavras-chave lixosas no e-mail, revelou-se
mais eficiente do que todos os outros até então criados.
nas finanças: Decidir, para um suplicante de um crédito,
sobre
a questão se conseguirá pagar as suas dívidas ou não,
a probabilidade que conseguirá pagar as suas dívidas,
sobre a quantia que lhe será concedida,
a partir
dos dados financeiros de credores anteriores e
dos seus desempenhos no pagamento das dívidas (quer dizer, faliu ou
cumpriu?).
no futebol: decidir se um jogador pertence à seleção nacional a
partir das
capacidades (físicas) de jogadores da Série A e
se foram nomeados.
1.3 Formalização
Formalmente, em um problema de aprendizado, temos
a entrada
,
a saída
,
os dados ou a amostra
(= um conjunto finito em
sobre o qual a função alvo é conhecida, isto é,
,
…,
são conhecidos, e
a função alvo (ou função de regressão ou
classificadora)
(= a função ótima, que sempre acerta, a ser aproximada; chamamo-la
também de função divina para exprimir que existe e é
aproximável com certa probabilidade, mas inatingível)
e
as hipóteses
(= um conjunto de funções que aproximam
),
e
uma medida de erro
que mede a diferença entre os valores da hipótese e os da função alvo,
e
um algoritmo (ou otimizador)
que escolhe uma função
em
que aproxima”
“o melhor”, em particular, minimiza
sobre
.
Enfatizamos que
a entrada, a saída, a amostra e a função alvo são
dadas,
as hipóteses e o otimizador são escolhidos pelo
programador.
As hipóteses e o otimizador são chamados o Método de
Aprendizado.
Observação. Mais adiante, a função alvo, em vez de ser uma
função determinista
,
será uma variável aleatória, isto é, intuitivamente, para cada
argumento
,
em vez de devolver
um único valor
,
devolve
ou para cada valor
uma probabilidade
(quando
é discreto, por exemplo, binário, finito ou
),
ou para cada intervalo de valores
uma probabilidade
(quando
é contínuo, por exemplo, um intervalo
,
a reta
,
ou o plano
).
(Em linguagem matemática, cada possível valor
constitui um evento cuja probabilidade
é medida pela distribuição, ou medida de
probabilidade,
.)
Porém, os valores
,
…,
para os dados
,
….,
continuam ser deterministas. O otimizador tem de deduzir as
probabilidades dos valores pelas suas frequências na amostra. Uma tal
função divina aleatória é chamada de uma função com ruído.
1.4 Formalização dos Exemplos
Nos exemplo
do diagnóstico, temos
= ênuplas de atributos médicos (= os de um paciente)
= doenças
= diagnósticos históricos
da classificação de e-mails em Spam ou
Ham, temos
= ênuplas do número de ocorrências de palavras (= os de um e-mail)
= Sim ou Não
= e-mails recebidos e suas classificações como Spam ou
Ham
da questão se um devedor poderá pagar as suas dívidas ou não, temos
= ênuplas de atributos financeiros (= os de um e-mail)
= Sim ou Não
= históricos de créditos concedidos
da composição da seleção nacional, temos
= ênuplas de capacidades (= as de um jogador)
= Sim ou Não
= seleções anteriores.
Observamos que os últimos três exemplos, a classificação de e-mails,
de credores e de jogadores, são exemplos de uma classificação
binária, isto é, a saída é binária.
Enquanto as ênuplas na classificação de e-mails têm muitos entradas
(já que existem muitas palavras), a dimensão dos outros dois exemplos é
menor e poderemos dar uma interpretação geométrica. Em mais detalhes,
olhamos, por exemplo
a avaliação da solvência de um possível devedor por um banco. A
entrada
aqui são os dados financeiros de um cliente, por exemplo
idade
salário
haveres
dívidas
a avaliação da aptidão de um jogador para a seleção nacional. A
entrada
aqui são os dados físicos do jogador, por exemplo a velocidade
do chute, e
do jogador
1.5 Pontuação
Nestes dois exemplos, da discriminação entre credores e jogadores
aptos,
a entrada pode ser interpretada como ênupla de números reais, e
a saída é binária: Sim e Não.
Neste caso, podemos dar uma pontuação ao possível devedor ou
ao jogador relativo aos seus atributos financeiros ou físicos. Mais
explicitamente, avaliar as suas importâncias (ou
pesos) e somar os atributos (features)
pesados. Se esta soma é suficientemente alto, quer dizer, em cima de um
certo limiar, aceitamos o devedor ou jogador.
Por exemplo,
para certo Neymar, a velocidade
do chute é 100 km por hora, e
do jogador é 40 km por hora;
para certo Roberto Carlos, a velocidade do
do chute é 200 km por hora, e
do jogador é 20 km por hora;
para certo Frederico, a velocidade do
do chute é 100 km por hora, e
do jogador é 20 km por hora
Por exemplo, poderíamos dar,
peso
à velocidade do jogador, e
peso
à velocidade do chute.
Obtemos,
para Neymar a pontuação
para Roberto Carlos a pontuação
para Frederico a pontuação
Se Neymar e Roberto Carlo estão na seleção nacional, mas Frederico
não, então, por exemplo, um limiar de
modela isto.
Geometricamente, - os dois atributos de um jogador correspondem a um
ponto no plano cartesiano, e - os pesos e o limiar a uma
reta que separa entre os jogadores na seleção nacional e o
resto.
Aplicaremos em Seção 4.1 o método
geométrico do otimizador Perceptron, ou, um nome mais
expressivo, Discriminador Linear que busca (ou
aprendre) esta reta.
Observamos que estes pesos separam perfeitamente para a nossa
amostra, mas provavelmente, estes mesmos pesos falham com outra. Por
exemplo, os pesos obtidos pela seleção pelo Filipão (em 2006) são bem
diferentes dos pelo Tite (em 2018). Isto toca a questão do aprendizado
discutida em Seção 2: Quando podemos
dizer que a amostra é típica e nos levou a uma boa escolha dos
pesos?
2 O que é aprendizado?
Recordemo-nos de que formalmente, em um problema de aprendizado (com
supervisionamento), temos os dados, isto é,
a entrada
a saída
a amostra
(= um conjunto finito em
sobre o qual a função alvo é conhecida, isto é,
,
…,
são conhecidos, e
a função alvo (ou divina)
(= a função ótima, que sempre acerta, a ser aproximada)
e o método, isto é,
as hipóteses
(= um conjunto de funções que aproximam
),
e
um algoritmo
que escolhe uma função
em
que aproxima”
(e em particular
)
o mais possível.
2.1 Erro
A escolha da proximidade, ou melhor, da distância mais apropriada do
erro, isto é, entre os valores da hipótese
e da função divina
,
depende, entre outros, da saída
.
O que significa a
mais próxima de
?
Esta escolha faz parte da definição do algoritmo
:
Por exemplo,
quando
é binária, isto é, existem os dois erros
,
mas
e vice versa
,
mas
,
podemos atribuir a cada erro a mesma importância, isto é, definir a
distância pelo número de erros
podemos distinguir entre as gravidades
e
dos erros (por exemplo, quando pensamos na deteção de uma doença grave e
contagiosa como HIV, é menos grave detetar à toa, um falso positivo
,
do que deixá-la passar impercebida,
),
isto é, definir o erro por
quando
,
gostaríamos de tomar em conta o tamanho da diferença
em cada ponto
;
usualmente, usa se a diferença quadrática a este fim, isto é
O programador determina
as hipóteses
,
e
a medida do erro na amostra
,
e
em seguida
o algoritmo
que busca a hipótese
que minimize
.
Porém, isto não quer dizer que
minimize o erro fora da amostra, isto é, se aproxime da função divina em
todo lugar. Esta proximidade depende da escolha justa de
e
.
Formalismo
Será a função de custo que capta todas as possíveis medidas
de erro neste manuscrito. Quando a saída é binária, e as importâncias
dos dois erros
,
mas
e, vice versa,
,
mas
,
são iguais, basta contar os pontos em que
erra (isto é, difere de
)
isto é,
Porém, em geral precisamos de uma abordagem mais geral à avaliação da
proximidade de
à função divina
:
para uma saída binária
,
isto é, os dois erros
,
mas
e, vice versa,
,
mas
,
queremos distinguir entre as gravidades
e
dos erros, ou
para
,
queremos tomar em conta o tamanho da diferença
em cada ponto
A este fim, introduzimos a função de custo
tal que
A função de custo faz parte do
algoritmo; isto é, a sua apropriada escolha é sob a
responsabilidade do programador do algoritmo.
Por exemplo,
Quando
,
sim ou não, e queremos tomar em conta que o erro
que
mas
é muito mais grave
que
,
mas
.
Por exemplo, é muito mais grave um leitor de dedo num caixa
eletrônico
aceitar uma impressão digital erroneamente como a dono do cartão de
crédito
do que
rejeitar erroneamente a do dono.
Por exemplo, se o primeiro erro é
vezes mais grave, isto é,
\
obtemos
Isto é, a função de custo
é dada por
,
(e
alhures).
Quando
,
e queremos tomar em conta a distância entre
e
,
a escolha mais comum é o valor médio da diferença quadrática,
isto é,
.
Usa-se, por exemplo, na regressão linear. Observamos
que o quadrado
(em vez do valor absoluto
) penaliza poucos pontos muito distantes mais do que muitos pontos pouco
distantes; por exemplo,
erro de uma distância de
mais do que
erros de uma distância de
;
que se
,
então
se e tão-somente se
.
Isto é, a função de custo para funções reais generaliza a função de
custo de contagem (isto é, que conta os erros) de para funções cujos
valores são binárias.
Quando
,
isto é,
é uma (media de) probabilidade, a melhor escolha para a hipótese
(parametrizada por certos parâmetros como a média e a variância da
probabilidade) a partir da amostra
e os resultados
é, segundo o princípio da máxima verossimilhança, aquela
escolha que maximiza a probabilidade
da observação dos valores
dada a amostra
.
Isto é,
Para
,
…,
independente e identicamente distribuídos, após aplicação do logaritmo
(ao negativo), queremos minimizar o erro logarítmico (a verossimilhança
logarítmica, ou log-likelihood em inglês)
Isto é, a função de custo para cada
exemplo é
Como estamos mais interessados em minimizar o erro do que no seu
valor exato, podemos aplicar uma função monótona
ao estimador do erro
,
por exemplo, como acima, o logaritmo
(para diminuir valores muito grandes). Isto é, como
é monótona, a composição
é mínima se e tão-somente se
é mínimo.
2.2 Provavelmente
Aproximadamente Correto
O que significa
aprendizado?
Isto é, qual é o nosso alvo no aprendizado de máquina?
Segundo o princípio PAC (Provavelmente Aproximadamente
Correto) é, encontrar um algoritmo que consegue a partir de quase
qualquer amostra (isto é, Provavelmente) encontrar uma
função que quase sempre acerta (isto é, que é
Aproximadamente Correta):
Uma hipótese mostra bom aprendizado se tira as conclusões certas a
partir de uma amostra; isto é, mais importante do que acertar na amostra
é acertar na entrada inteira
:
Seja, por exemplo, a saída
binária, isto é, um problema de classificação binária. Dada a amostra
e uma função
,
podemos calcular o erro específico por
isto é, a probabilidade que
erre sobre
.
(Em Abu-Mostafa,
Magdon-Ismail, e Lin (2012), denotado por
para significar dentro da amostra.) Por exemplo, o algoritmo
Perceptron, se termina, consegue
.
Mas, como
é desconhecida, não sabemos o erro geral,
isto é, a probabilidade que
erre sobre
.
(Em Abu-Mostafa,
Magdon-Ismail, e Lin (2012), denotado por
para significar fora da amostra.)
Veremos quando podemos minimizar esta probabilidade de erro. Porém,
depende sempre da amostra, que pode ser atípica e levar mesmo um bom
algoritmo à escolha de uma hipótese que tira conclusões erradas. Isto é,
o algoritmo pode só acertar com certa probabilidade na escolha de uma
hipótese próxima (a função divina); isto é, é provavelmente
aproximadamente correto.
Formalismo
Dada a amostra
e uma função
,
podemos calcular o erro específico,
isto é, a probabilidade que
erre sobre
.
(Em Abu-Mostafa,
Magdon-Ismail, e Lin (2012), denotado por
para significar dentro da amostra.) Por exemplo, o algoritmo
Perceptron, se termina, consegue
.
Mas, como
é desconhecida, não sabemos o erro geral (ou erro
de generalização),
isto é, a probabilidade que
erre sobre
.
(Em Abu-Mostafa,
Magdon-Ismail, e Lin (2012), denotado por
para significar fora da amostra.)
Se, por exemplo,
e
(classificação binária), e
tem
pontos,
qualquer função que coincide em
com
é uma possível solução; sobram
valores a definir. Qual destas
extensões dos
aos
pontos é a mais próxima da função alvo? Não há resposta definitiva, mas
provavelmente aproximadamente correta:
O problema é apreensível por PAC ( = Provavelmente
Aproximadamente Correto) se existe um algoritmo
que calcula para qualquer amostra
uma hipótese
em
que seja provavelmente aproximadamente correta, isto é:
Para todo (erro)
e (toda difidência)
e para toda distribuição (= medida de probabilidade)
,
existe um
tal que para toda amostra
com pelo menos
exemplos independente e identicamente distribuídos
Para o algoritmo
ser eficientemente computável, é mais exatamente requerido que
para um polinómio
,
chamado de complexidade de amostra do algoritmo
.
Recordemo-nos de que
a integral
mede o erro geral entre
e
(
= Aproximadamente Correto), e
a probabilidade
mede o conjunto (em
)
em que a ênupla
implica uma escolha
pelo algoritmo
que é próxima de
,
isto é, tal que o erro
;
como é
,
é, em palavras, (altamente) provável.
Isto é, provavelmente a amostra leva a uma hipótese
aproximadamentecorreta. Quer dizer,
se a amostra é suficientemente típica (o que vale com uma probabilidade
,
isto é, provavelmente), então a probabilidade do erro é
pequena,
,
isto é, a função é aproximadamente correto.
Em Seção 3, dados
e
,
calcularemos para uns problemas de aprendizado o tamanho
da amostra
que garante que
2.3 Treinar e Testar
Como saber se um método aprende bem, isto é, se a hipótese
escolhida pelo algoritmo
a partir de
tem um erro geral
pequeno?
Holdout
Na prática, uma abordagem é o holdout, isto é, não usar toda
a amostra
para a computação da melhor escolha
por
,
mas divide aleatoriamente
em dois subconjuntos
e
,
por exemplo,
dos exemplos em
e
dos exemplos em
para
usar o conjunto
como amostra para a computação da melhor hipótese
,
o conjunto de treinamento, e
usar o conjunto
para verificar a hipótese
,
o conjunto de teste.
No treinamento, minimizamos
(sobre todas as hipóteses
).
No teste, verificamos que
é pequeno.
Se a saída é finita,
,
então o erro de teste
é visualizado por uma matriz de confusão, por exemplo, para
com
exemplos de cada tipo
,
e
,
\
onde
as casas na diagonal indica o número de exemplos que foram acertados
e
as outras o número dos que foram confundidos.
Random Subsampling
Se o alvo do programador, em vez de encontrar pelo algoritmo a
melhor hipótese a partir de uns exemplos (e em seguida medir o erro
da hipótese para outros exemplos), é medir a média dos erros
das hipóteses encontradas pelo algoritmo (isto é, em vez de medir a
acuraria da hipótese, medir a acuraria do algoritmo), então se aplica,
em vez do holdout, o random subsampling que varia o conjunto de
teste: Divide
em, no mínimo, três subconjuntos
,
e
e
usa
como conjunto de teste (e
como conjunto de treinamento),
usa
como conjunto de teste (e
como conjunto de treinamento), e
usa
como conjunto de teste (e
como conjunto de treinamento).
O nosso método
Neste manuscrito, porém, só treinamos, e não testamos:
Confiaremos em que o método, isto é, as escolhas
de
,
da medida de erro
,
e
do algoritmo
são suficientemente apropriadas para o problema de aprendizado
aprenda bem, isto é, que a minimização do erro da amostra
(entre todas as
em
)
garante um erro geral
suficientemente pequeno (sem avaliar
para um conjunto de teste
diferente de
).
3 Quão bem aprendemos?
O que é aprendizado? Afinal, queremos encontrar a partir de uma
amostra, uns exemplos (por exemplo, clientes antigos de um
banco) uma função simples, a hipótese, que prediz os valores em
que nos interessamos (por exemplo, a quantia de um crédito) para outras
entradas (isto é, futuros clientes).
Para o algoritmo acertar, quer dizer, fazer provavelmente um erro
pequeno, precisamos muitos exemplos, clientes antigos. Nesta Seção
descobrimos
para quais problemas o algoritmo consegue provavelmente acertar,
e
caso consiga, quantos exemplos precisa para isto.
Para isto, usamos uma estimativa geral, a desigualdade de Hoeffding
(estatístico finlandês) que inicialmente só se aplicou para um número
finito de hipóteses. Infelizmente, na prática o número de hipóteses é
infinito. Por exemplo, no Perceptron no plano, as hipóteses
são todas as retas.
Por isso, restringimos as hipóteses da entrada inteira infinita
à amostra finita
.
Por exemplo, no Perceptron, restringimos aos valores das
retas sobre
pontos no plano. Vimos que já para
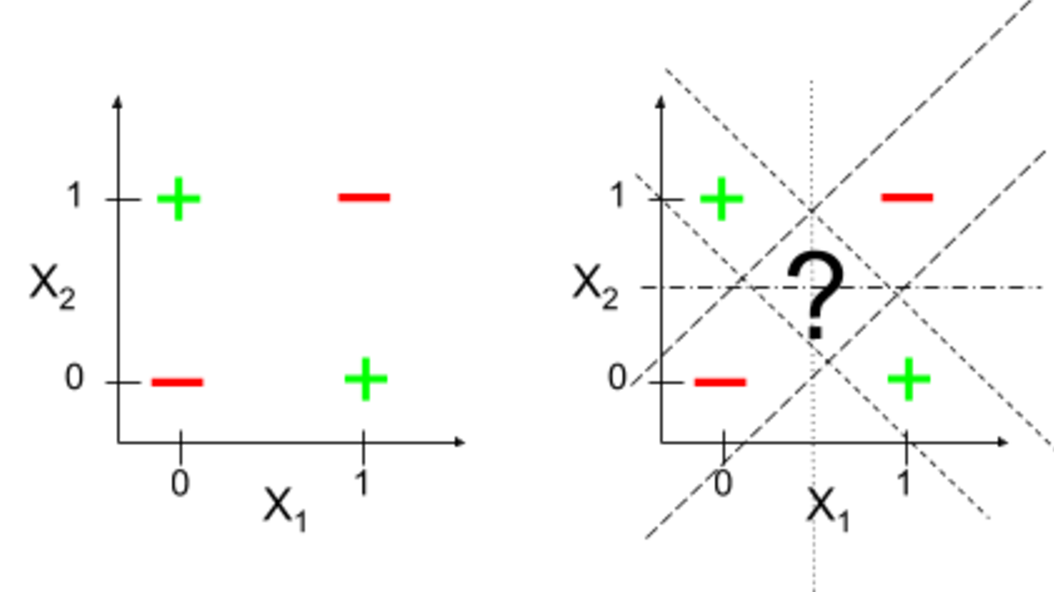
,
tem valores de pontos que nenhuma reta consegue reproduzir, quer dizer,
não existe reta que os separe, por exemplo:
+
- -
+
Quando um tal número como
existe em que as hipóteses são insuficientes para reproduzir uma
classificação da amostra, diremos que a dimensão (de
Vapnik-Chervonenkis)
das hipóteses é finita. Neste caso, podemos, para qualquer erro
e para qualquer confiança
,
por exemplo,
e
,
garantir que a hipótese escolhida pelo algoritmo a partir de uma amostra
com
exemplos faça um erro
com uma probabilidade de
.
O resultado teórico é muito folgado, pois muito geral: Na teoria,
,
na prática
.
Por exemplo, para o Perceptron no plano,
.
3.1 Defeito
Dada a amostra
com os seus valores
e uma hipótese
,
podemos calcular o seu erro específico,
contudo, como
é desconhecida, não o seu erro geral,
cuja minimização é o alvo final. Para
aproximá-lo, introduzamos o defeito
que quantifica quão bem o algoritmo
aprende, tira conclusões gerais certas a partir da amostra
:
Para limitar
,
precisamos, pela desigualdade triangular
de limitar
Isto é, a viabilidade de aprender
corresponde à viabilidade de minimizar
o defeito
,
e
o erro específico
.
Para simplificar a exposição, seja daqui em diante
,
problema de classificação binária, e o erro
dado pela probabilidade de errar.
3.2 Desigualdade de Hoeffding
Teorema. Dada uma função
,
um limiar de erro
e um número de exemplos
,
a desigualdade de Hoeffding estima a probabilidade do
defeito ser
por
Isto é, dada uma hipótese
,
sabemos limitar a probabilidade do evento
de uma amostra
atípica, isto é, em que o erro de
difira do erro geral de
por mais de
,
por um grande número de exemplos
.
Num problema de aprendizado, dada uma função
,
um limiar de erro
e um número de exemplos
,
queremos limitar o risco
que uma amostra
leva o algoritmo a uma hipótese
errada, isto é, com
.
Como
e como
é conhecido, queremos limitar
,
isto é, a probabilidade do evento
de uma amostra
atípica, isto é, em que o erro de
difira do erro geral de
por mais de
.
Para estimar
pela aplicação da desigualdade de Hoeffding, observamos que
no evento da desigualdade de Hoeffding, a função é fixa,
independente de
,
enquanto
no evento
,
a função varia com
!
Em geral, sem conhecimento do algoritmo que escolhe
a partir de
,
só podemos limitar a probabilidade de
para
pela probabilidade que
para uma
em
.
Isto é, que exista
em
com
;
em fórmulas
Se
é finito, então
onde, na última desigualdade, como
,
…,
não variam com
,
aplicamos a cada um dos
parcelas a mesma desigualdade de Hoeffding, obtendo na soma o fator
.
Observação. Quanto maior
,
tanto mais facilmente o algoritmo consegue diminuir
mas, também, tanto maior o limite da
desigualdade
Não há saída deste dilema entre o erro
geral e o erro específico, só podemos procurar um equilíbrio entre os
dois.
3.3 A dimensão de
Vapnik-Chervonenkis
Recordemo-nos de que para uma hipótese
e uma amostra
,
é a diferença, o defeito
a diferença entre
o erro específico
(sobre a amostra
)
e
o erro geral
(sobre
).
quantifica quão bem o algoritmo aprende, acerta as conclusões gerais
a partir de exemplos. Logo, num problema de aprendizado, dada
,
queremos limitar a probabilidade
para a hipótese
em
que é escolhida a partir de
pelo algoritmo
;
em particular, que vária com
.
Como
é desconhecido, logo
,
precisamos de limitar o supremo de todas as hipóteses
Observamos
Por isso, se
é finito, esta probabilidade pode ser estimada, da maneira mais grossa,
por
Porém, para
infinito, precisamos de uma maneira mais fina para estimar
que toma em conta as grandes interseções dos conjuntos
para as
em
que diferem pouco.
Vamos agora conhecer a “dimensão” do conjunto de hipóteses
,
que permite limitar o defeito para
infinito.
O número
efetivo de hipóteses sobre uma amostra
Para limitar a probabilidade de um alto defeito,
em vez do número total
infinito de hipóteses, isto é, como funções sobre
inteiro,
estudamos o crescimento o número finito
das suas restrições a amostras
(conjuntos finitos em
)
crescentes.
Definição: O conjunto das restrições a
das hipóteses
em
,
as dicotomias geradas por
,
é denotado por
A função de crescimento
para
(sobre
)
é definida por
Se
,
então
onde os fatores
,
…,
correspondem aos dois possíveis valores
de
,
…,
;
logo,
Observamos nos exemplos seguintes de
para
diferentes que
o seu valor máximo
é frequentemente só alcançado para argumentos pequenos
,
e
quanto maior o número dos parâmetros que definem
,
tanto mais argumentos (pequenos sucessivos) alcançam este máximo:
Exemplos:
Seja
o plano e
o conjunto das hipóteses do Perceptron. Observamos que
é máximo, mas para
há para qualquer amostra
uma dicotomia
que não pode ser gerada por
.
Isto é, sempre podemos rotular quatro pontos no plano tal que eles não
sejam linearmente separáveis. (Isto é, o Perceptron não
termina.)
Figura 3.1: Quatro pontos linearmente
inseparáveis
Com efeito,
.
Para
e
,
temos
:
como
pontos cindem a reta em
segmentos, há
escolhas para
relativo a estes segmentos.
Para
e
com
se
está no intervalo
(e
caso contrário), temos
:
Como
pontos cindem a reta em
regiões, há
a escolha que o intervalo está inteiramente incluso em um destes
segmentos, e
mais
escolhas para a primeira extremidade e
escolhas sobrantes para a segunda extremidade do intervalo, sem importar
a ordem cronológica da escolha das extremidades; isto é,
escolhas.
Seja
o plano e
a família dada pelos conjuntos convexos (isto é, para cada dois
pontos no conjunto, também o segmento entre eles fica no conjunto) em
,
isto é,
se
está no conjunto convexo que corresponde a
.
Para mostrar que
é máximo, olhamos a amostra
dada por
pontos na borda de um círculo. Para qualquer dicotomia, conecta todos os
pontos do tipo
por um polígono convexo (assim que todos os pontos do tipo
estão fora dele).
Se
,
isto é, se existe uma amostra
tal que
,
dizemos que
estilhaça
.
Caso contrário, se
,
isto é, se nenhuma amostra de cardinalidade
pode ser estilhaçada por
,
o número natural
é um ponto de interrupção para
.
Exemplos: Nos exemplos acima, o menor ponto
de interrupção é
e
.
Para obter
,
usa-se uma rotulagem (= dicotomia) sobre os pontos que é inestilhaçável,
isto é, não pode provir de uma hipótese.
Definição: A dimensão de
Vapnik-Chervonenkis é
e
caso
para todos os
.
Isto é,
para
o menor ponto de interrupção para
.
Para calcular
,
limitamos
abaixo e acima: Por definição,
ou, equivalentemente, em
contra-posição,
Exemplo: Para o Perceptron sobre
,
temos
.
Por exemplo, para
,
temos
.
Em geral, como heurística,
é proporcional ao número dos parâmetros que definem as funções em
.
Cota do
número efetivo de hipóteses sobre uma amostra
Dada uma amostra
com
elementos,
,
recordemo-nos da desigualdade de Hoeffding, para um conjunto de
hipóteses finito de cardinalidade
,
Logo, com
,
resolvendo para
,
obtemos
Para
infinito, queremos substituir
pelo número
(que depende de
)
e limitá-lo. Revela-se
que a fórmula de Hoeffding precisa de uma leve modificação para esta
substituição valer,
que, se há um ponto de interrupção, então
pode ser limitado por um polinômio em
.
Teorema(Lema de Sauer): Se há
em
tal que
,
então
para todos os
.
Em particular, para
a dimensão de Vapnik-Chervonenkis,
para todos os
.
Isto é,
é limitado por um polinômio de grau
.
Corolário. Se
,
então
Demonstração: Por indução em
.
Cota de erro
Teorema(Cota de Generalização de VC = o
mais importante resultado matemático na teoria de aprendizado): Para
,
Corolário: Se
,
então para qualquer
e
existe
tal que, para toda amostra
com
,
Mais exatamente, para todo
com
Demonstração: Se
,
então pelo Lema de Sauer,
Como
,
logo
para qualquer polinômio
,
obtemos
Mais exatamente, podemos resolver
para
,
obtendo a desigualdade para
acima.
Vemos que
exatamente porque
é polinomial, e não exponencial,
.
Neste caso, valeria
;
em particular, não converge a
.
Observação. Porém, a desigualdade
é implícita, isto é,
aparece ao lado direto. Por isso,
precisa de ser aproximado iterativamente: Se
,
onde
denote o lado direito, então o crescimento monótono da função
permite aproximar o mínimo
tal que
pelos valores
,
,
…
Por exemplo, para
,
uma confidência
e erro
,
uma escolha
leva a um valor no lado direto de
.
Esta iteração converge rápido a um valor de
.
Semelhantemente, para
e
,
obtém-se
e
.
Isto é, o número de exemplos requerido é proporcional à dimensão de
Vapnik-Chervonenkis com um fator de
.
Na prática, um fator de
revelou-se suficiente (vide Deep Learning para um método de
aprendizado que funciona bem na prática mas desafia o quadro teórico de
Vapnik-Chervonenkis).
Contudo, apesar da cota demasiada ampla, as estimativas obtidas por
Vapnik-Chervonenkis são
as únicas que funcionam em geral, e outras abordagens gerais não
levaram a melhores resultados, e
já expõem fenômenos gerais como a proporcionalidade entre
o número de exemplos necessários para obter uma hipótese
provavelmente aproximadamente correta, e
o número de parâmetros que definem as hipóteses, isto é,
.
4 Hipóteses Lineares
Muitos problemas de aprendizado podem ser resolvidos por hipóteses
que são funções lineares. Para três saídas diferentes,
a saída binária,
a saída ilimitada,
,
e
a saída probabilista,
vamos explicar três algoritmos que escolhem entre tais hipóteses:
o Perceptron ou Discriminador Linear,
a Regressão Linear, e
a Regressão Logística.
Por exemplo, um banco pergunta-se sobre um cliente:
se ele deve receber um crédito (sim ou não)?
qual é a quantia do crédito (um número real)?
quão provável é que ele quite as contas (uma probabilidade) ?
Recordemo-nos de que em um problema de aprendizado, temos um
algoritmo
que escolhe em função da amostra
a melhor hipótese
em
.
A melhor hipótese quer dizer a hipótese que é mais próxima da
função divina
.
A proximidade de
mede-se pela função de erro geral
,
o erro sobre
.
Como
é só conhecida sobre
(mas não sobre
),
podemos só aproximá-lo pelo erro específico
sobre a amostra
.
Em todos os algoritmos lineares que serão apresentados,
cada hipótese
corresponde a um vetor de pesos
em
,
mais exatamente
para uma função
que
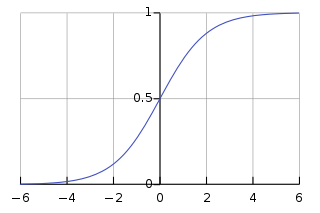
é
,
o sinal, no Perceptron,
é
,
a identidade, na Regressão Linear, e
é
,
a função logística, na Regressão Logística;
o erro especifico
é uma soma finita nos valores
,
…,
sobre a amostra
.
Em todos os algoritmos lineares que serão apresentados,
contentamo-nos com um algoritmo
que para cada
escolhe o
que minimize esta soma finita
nos valores
,
…,
.
Frequentemente, acrescentamos uma coordenada constante a
,
isto é,
como artifício para aumentar a dimensão de
e preservar a dimensão de
.
Isto permite dispensar de um parâmetro constante nos algoritmos, isto é,
em vez de
basta-nos considerar
pelo acréscimo de uma entrada
.
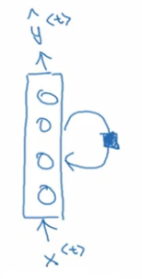
4.1 Perceptron (ou Discriminador
Linear)
Formalizemos a questão de como decidir se um cliente consegue quitar
um crédito a partir dos seus atributos (features) por
comparação com as quitações históricas.
A ideia é pontuar o cliente, e conceder o crédito caso a pontuação
foi suficientemente alta. Isto é, dar pontos aos clientes de um banco em
relação aos seus atributos financeiros, por exemplo, o seu salário e os
seus bens. Se a pontuação é suficientemente alta, o crédito lhe é
concedia.
A questão surge como ponderar os atributos dos clientes, quais pesos
dar aos seus atributos, e onde localizar o limiar a partir de que será
aceito?
O algoritmo que busca estes pesos chama-se Perceptron: Mais
abstratamente, se o problema de aprendizado é uma classificação
binária, isto é
,
e
,
podemos aplicar o método de aprendizado do Perceptron,
em que
com
se
e
se
.
Isto é, uma função
em
é dada pelos
seus pesos
e
o seu limiar
(= a nossa pontuação mínima),
e, para
em
,
vale
Geometricamente, os pontos
que satisfazem a igualdade
formam um hiperplano que divide o espaço
nos dois semiespaços dos pontos
cuja soma é
).
Por exemplo, se
é o plano, a igualdade define uma reta e cada lado dela um semiplano. Se
as coordenadas sejam denotadas por
e
,
os pesos por
respetivamente
,
então a equação da reta como função no argumento
com valor
é dada por
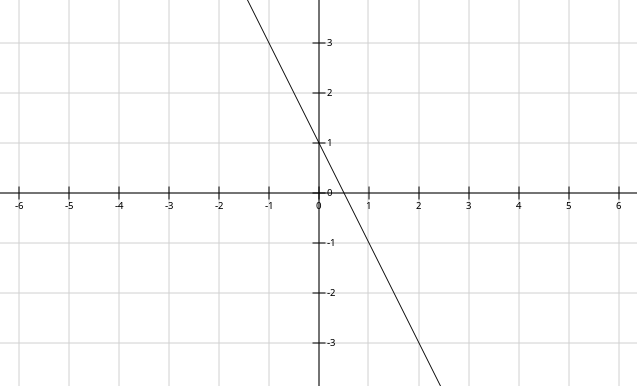
Por exemplo, os parâmetros
,
e
correspondem à reta abaixo:
A reta
divisa o plano nos dois semiplanos
No caso
da concessão de um crédito, dependendo dos dados financeiros de um
cliente e da importância de cada critério: Entre os pesos, revelam-se
uns positivos, por exemplo, os haveres e o salário,
outros negativos, por exemplo, as dívidas;
da seleção de jogadores para a equipa nacional: Em Seção 1.5, concordamos que a velocidade do jogador
importa bem mais do que a do seu chute; em números,
o peso da velocidade do jogador foi
,
e
o da velocidade do chute foi
;
da detecção de um e-mail como Spam dependendo de quais
palavras o e-mail contém e as suas frequências em (e-mails de)
Spam e em (e-mails de) Ham. Por exemplo, são
pesos
positivos palavras de propaganda e de marcas, como
promoção, aumento ou Viagra,
negativos palavras como conjunções hesitantes, por exemplo,
entretanto, ou nomes raros de conhecidos, como
Elivélton.
O algoritmo Perceptron aproxima os pesos e o limiar por
iteração sobre todos os pontos no conjunto de dados exemplares
a uma solução
,
quer dizer, tal que
Hipóteses
Facilitemos a formulação do problema do aprendizado: Para abreviar a
notação da soma dos atributos pesados
,
usamos o produto escalar entre o vetor
e
dado por
(A notação
significa vetor transposto. Isto é, o vetor
é visto como vetor de coluna e
como vetor de linha. O produto escalar é o produto da
matriz de uma coluna
com a matriz de uma linha
.)
Pondo
e
,
vale
isto é, para
e
,
Concluímos que
,
e
,
e
com
se
e
se
.
(Geometricamente, para
,
olhamos o plano com as coordenadas
e
como o hiperplano
dado pela equação
no espaço de três coordenadas
e
,
o hiperplano
no espaço dado pelos vetores ortogonais a
,
e
a interseção de
e
é a reta que separa os pontos.) Recordemo-nos de que
e
Erro
O erro especifico
que o algoritmo visa minimizar é o número dos pontos em que
erra,
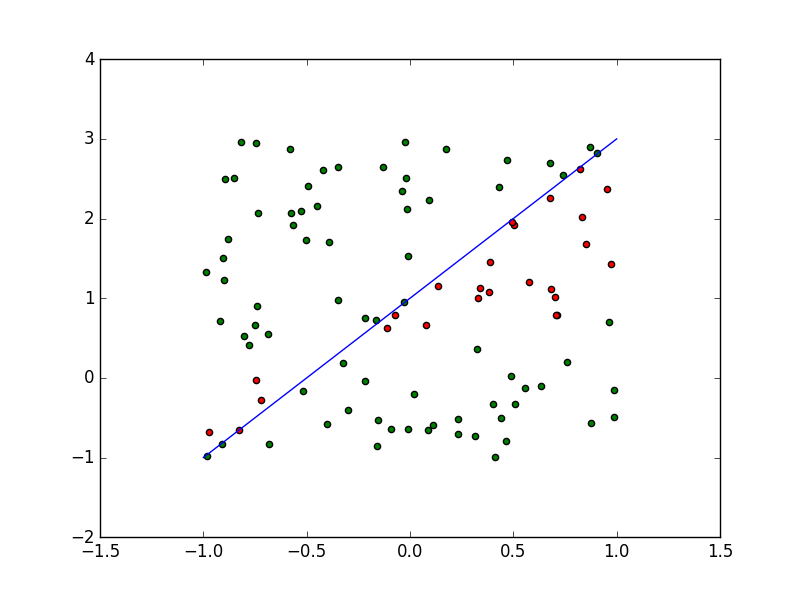
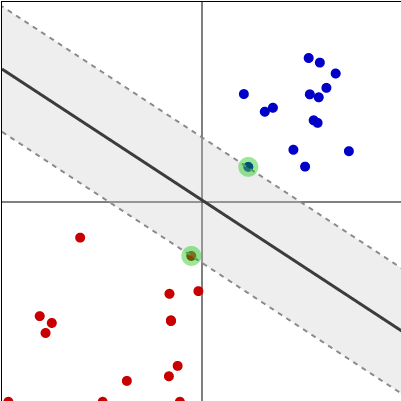
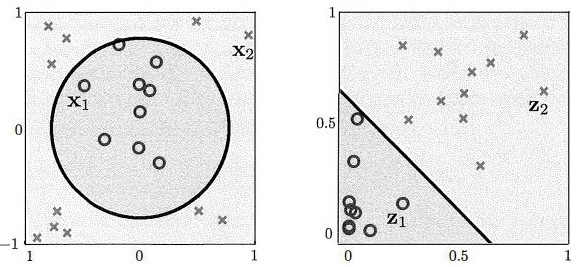
Na imagem correspondem:
o valor de
à cor do ponto, e
o valor de
ao lado da reta em que se encontra o ponto.
Separação de pontos pelas suas cores e
por uma reta
(Equivalentemente, o algoritmo visa minimizar
,
a probabilidade que
erre sobre
.)
Com efeito, o algoritmo Perceptron
ou consegue
,
ou oscila sem convergir.
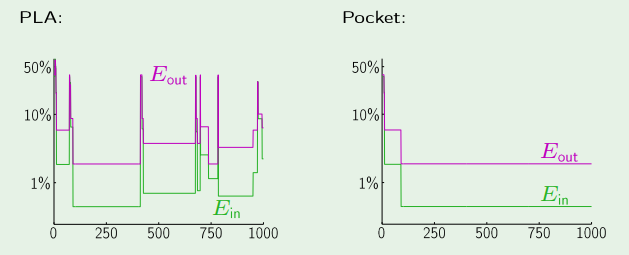
Por isso, apresentaremos em seguida o algoritmo Pocket
que remedia esta oscilação por iteração sobre o Perceptron.
Assim, converge mesmo quando
é impossível.
Algoritmo
O algoritmo Perceptron determina o limiar e os pesos
iterativamente a partir da amostra
como segue:
Seja
a iteração e
o valor de
na iteração
.
Seja
em
um ponto erroneamente classificado e
o seu valor correto. Formalmente, erroneamente classificado
quer dizer
ou, equivalentemente,
ponto erroneamente
classificado
O Perceptron põe
Geometricamente, para obter a nova reta
(= o novo limiar e os novos pesos)
,
o Perceptron desloca a reta na direção correta (isto é, a
dada por
)
do ponto erroneamente classificado. Formalmente, há duas
possibilidades:
ou
e
,
ou
e
.
Como
e
para qualquer vetor
,
vale
se
e
,
então
,
se
e
,
então
Isto é, o valor da (nova) função hipotecada
é pelo menos no ponto por enquanto erroneamente classificadomais próximo do valor correto (do que o da antiga função
hipotecada
).
(Isto não quer dizer que a cada iteração o erro em outros pontos pode
aumentar! Diante disto é estupefaciente que a função finalmente obtida é
totalmente correta — dado que uma tal função existe.)
O Perceptron itera a correção do limiar e dos pesos
até que não haja mais pontos erroneamente classificados.
Geometricamente, desloca a reta até que separe as duas classes de
pontos.
Código
Se denotamos a amostra por
e os seus valores sob a função divina
por
,
então, em pseudo-código, o algoritmo Perceptron é dado
por
Põe
e
Repete
Para
Se
,
então põe
Aumenta
por
até
para todo
Devolve
import numpy as npX = np.array([ [-2, 4], [4, 1], [1, 6], [2, 4], [6, 2]])Y = np.array([-1,-1,1,1,1])def perceptron(X, Y): w = np.zeros(len(X[0])) epochs =100for t inrange(epochs): errors =0for i inenumerate(X):if (np.dot(X[i], w)*Y[i]) <=0: w = w + X[i]*Y[i] errors +=1if errors ==0:breakreturn w
Para desenhar os pontos classificados pela reta separadora,
from matplotlib import pyplot as pltfor d, sample inenumerate(X):# Plot the negative samplesif d <2: plt.scatter(sample[0], sample[1], s =120, marker ='_', linewidths =2)# Plot the positive sampleselse: plt.scatter(sample[0], sample[1], s =120, marker =' + ', linewidths =2)# Print the line computed by perceptron ()x2 = [w[0],w[1],-w[1],w[0]]x3 = [w[0],w[1],w[1],-w[0]]x2x3 =np.array([x2,x3])X,Y,U,V =zip(*x2x3)ax = plt.gca()ax.quiver(X,Y,U,V,scale =1, color ='blue')
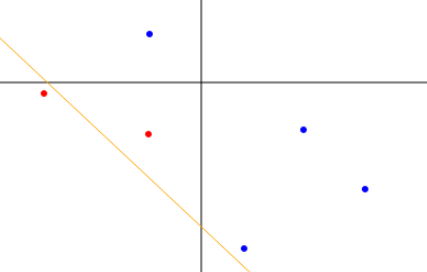
Exemplo em dois passos
Seja
,
e
consista
nos dois pontos
e
com
e
,
e
seja
.
Observamos que
satisfaz
se e tão-somente se
Isto é, descrevemos a projeção dos
vetores ortonormais ao vetor
aos seus últimos dois coordenados pela função (traslada) linear
.
Como
mas
,
constatamos que
é erroneamente classificado e determinamos
Isto é,
e
.
Como
e
,
constatamos que
é bem classificado (e
também) e o algoritmo termina.
O exemplo dado pelos pontos
e
Tempo de Execução
Se
não é linearmente separável, isto é, não há uma solução em
,
este algoritmo não converge a uma solução aproximativa (quer dizer, que
minimiza as classificações errôneas).
Se
é linearmente separável, quanto maior a margem entre os dois conjuntos
de pontos, tanto mais fácil a sua separação, isto é, tanto mais rápido o
Perceptron converge. Mais exatamente, este algoritmo termina em
passos onde
é o raio de
,
e
é a margem, a máxima distância de um hiperplano (= uma reta
quando
é o plano) entre os dois conjuntos dos pontos (onde a distância da reta
entre os dois conjuntos de pontos é a mínima distância entre ela e os
pontos).
A margem de um hiperplano separando dois
conjuntos de pontos
Em fórmulas, o raio e a margem são definidos como
segue:
o raio
de um conjunto de pontos
é definido por
para um hiperplano
(dado por
onde ortogonal significa
)
e dados
,
a margem entre
e
é
onde, para um hiperplano
,
a distância entre ele e um ponto
é definida por
(Recordemo-nos de que, para dois
vetores
e
no plano,
onde
é o angulo entre eles, e
e
são os seus comprimentos.)
Animação
Para ganharmos um intuito como o Perceptron se aproxima da reta
separadora, há uma animação
online (em JavaScript) da Universidade do Texas em
Austin.
O Algoritmo Pocket (=
bolso)
Recordemo-nos de que se o problema de aprendizado é um problema de
classificação binária, isto é,
(com
fatores) e
,
então no algoritmo Perceptron as hipóteses
têm a forma
para vetores
em
.
Recordemo-nos de que na formalização PAC (=
Provavelmente Aproximadamente
Correto) do aprendizado, buscamos
tal
que
seja próximo de
,
e
que
seja próximo de
.
O Algoritmo Perceptron
Se a amostra
é linearmente separável, isto é, há
em
tal que
então o algoritmo
Perceptron encontrará tal
.
Recordemo-nos de que, para cada passo
,
o Perceptron seleciona um ponto erroneamente classificado
com valor
e atualiza
por
Mas, se
não é linearmente separável, isto é, não há uma solução em
,
este algoritmo não converge a uma solução aproximativa (quer dizer, que
minimiza
,
as classificações errôneas).
O Algoritmo Pocket
Se
não é linearmente separável, isto é, é impossível achar
tal que
,
queremos pelo menos minimizá-lo, isto é, encontrar o (melhor) vetor de
pesos
(em
)
que minimiza
O algoritmo Pocket (=
bolso) aplica o Perceptron repetidamente (por exemplo, em
repetições) e guarda no seu bolso o melhor vetor de pesos
até então encontrado. Isto é,
Põe w := w(0)
Para t = 0, ..., T:
Roda um passo do Perceptron para obter w(t + 1)
Calcula E(w(t + 1))
Se E(w(t + 1)) < E(w), então põe w = w(t + 1)
Devolve w
Isto é, em comparação ao Perceptron, o
Pocket avalia após a atualização
se o novo vetor é melhor (quanto o erro sobre a amostra) do que o melhor
até então encontrado
,
e, caso sim, substitui
por
.
Pela computação de
,
que percorre todos os pontos da amostra, o algoritmo Pocket
é mais lento do que o Perceptron.
Sabemos
nem qual é o melhor vetor de pesos,
nem quando se encontrará.
A evolução do erro do
Perceptron contro o do Pocket
Recapitulação
Questões para quem quiser testar a assimilação do conteúdo desta
seção sobre o Perceptron:
Qual é a medida de erro que o algoritmo Perceptron minimiza?
Entre quais funções o Perceptron escolhe a melhor, isto é, que
minimiza o erro?
Quais parâmetros o Perceptron otimiza, isto é, quais números altera
até ter minimizado o erro?
O Perceptron consegue separar (por uma reta) qualquer rotulagem (=
escolha de cruzes e bolas) de quatro pontos no plano?
O número de erros sempre diminui após uma iteração adicional?
4.2 A Regressão Linear
O banco não somente quer decidir se o cliente recebe um crédito ou
não, mas mais exatamente estimar o seu valor.
Tem-se
(com
fatores) = os possíveis dados dos clientes (tais como bens, dívidas,
salário, idade),
= os possíveis valores dos créditos concedidos
e
= os dados históricos de clientes e os valores dos créditos que lhes
foram concedidos.
Hipóteses
Geometricamente, para
,
a regressão linear busca a reta
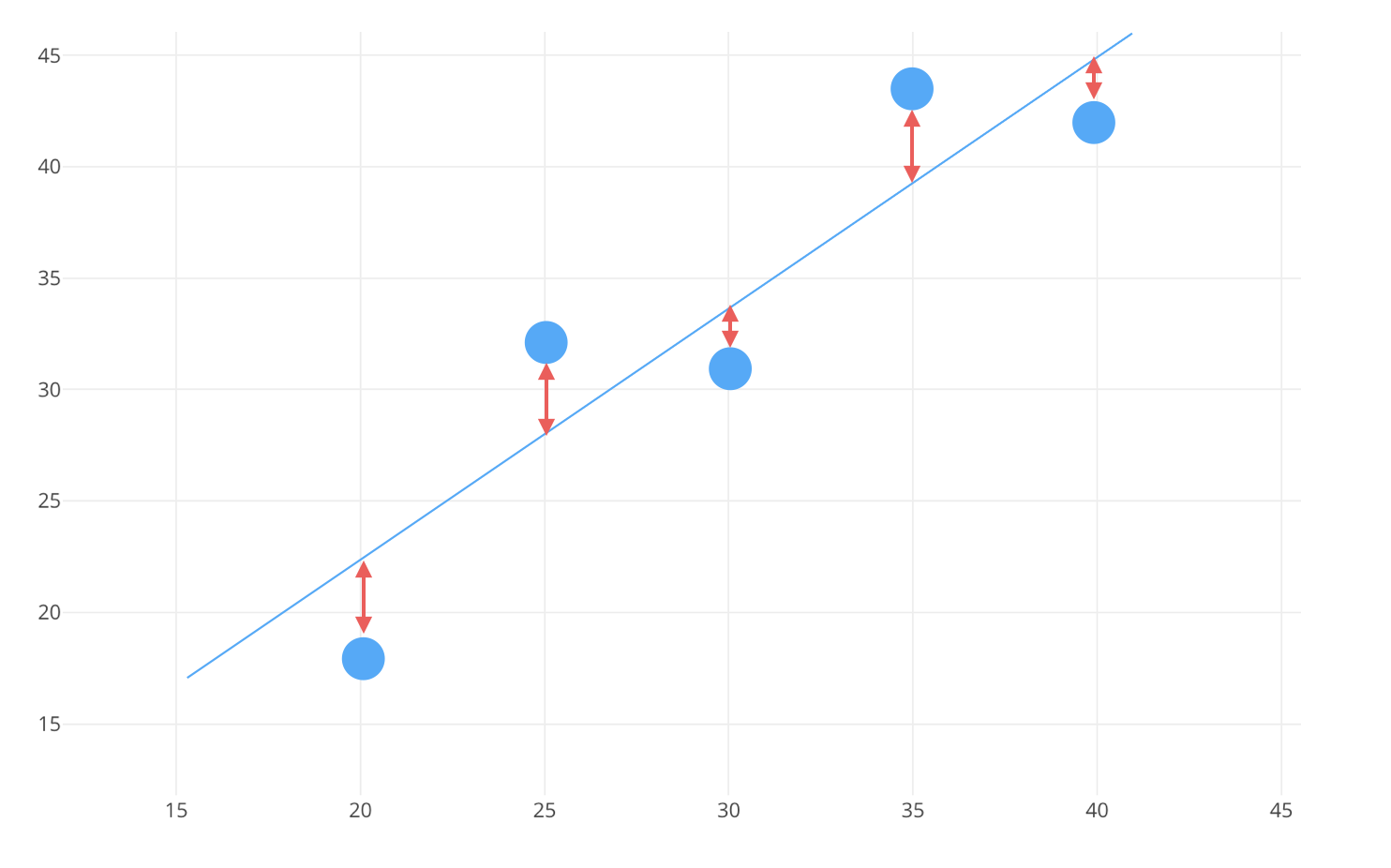
que minimize a distância (quadrática) aos pontos da amostra
.
As distâncias entre a reta
e os valores
,
…,
dos pontos da amostra
Cada hipótese
corresponde a um vetor
em
;
ela é dada por
Erro
O erro que queremos minimizar é a distância quadrática entre
e
,
isto é, o valor médio da diferença
ao quadrado sobre a amostra finita
,
onde a integral do valor médio se torna a soma finita
Cada hipótese
corresponde ao vetor dos seus pesos
.
Por isso, denotamos o erro especifico daqui em diante por
(em vez de
),
evidenciando como função em
.
Se denotamos
por
a matriz em
com as linhas
,
…,
em
,
e
por
o vetor coluna em
com as entradas
,
…,
,
então
onde
denote o vetor coluna cujas entradas são as do vetor
linha
,
e
denote a norma euclidiana, dada por
para um vetor real
,
isto é,
;
e onde
a primeira igualdade vale por definição de
,
e
a segunda igualdade vale porque os coeficientes do vetor
são
,
…,
.
Algoritmo
A regressão linear calcula o vetor
em
que minimiza
.
Se
,
podemos visualizar
a amostra
,
…,
e os seus valores
,
…,
sob a função divina
pelos pontos
,
…,
no plano, e
a hipótese
pela reta no plano que
se origina na altura
,
e
tem inclinação
.
(Isto é, é a função
cujo gráfico é a reta dada por todos os pontos
onde
percorre
.)
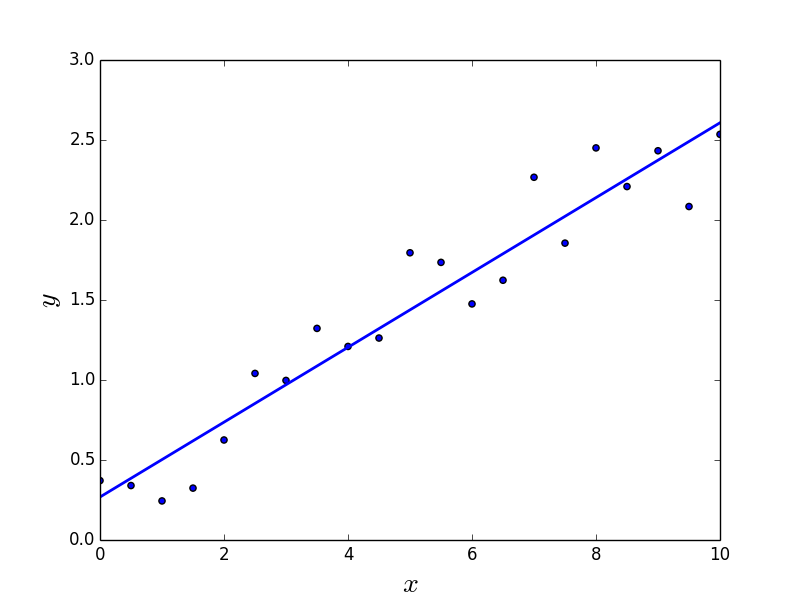
A reta dada pela Regressão Linear para
Com efeito, na Regressão Linear trata-se mais de uma fórmula do que
de um algoritmo. Daremos duas vias para demonstrá-la, obtendo o vetor de
pesos
que minimiza esta distância
como projeção de outro vetor a um espaço menor, e
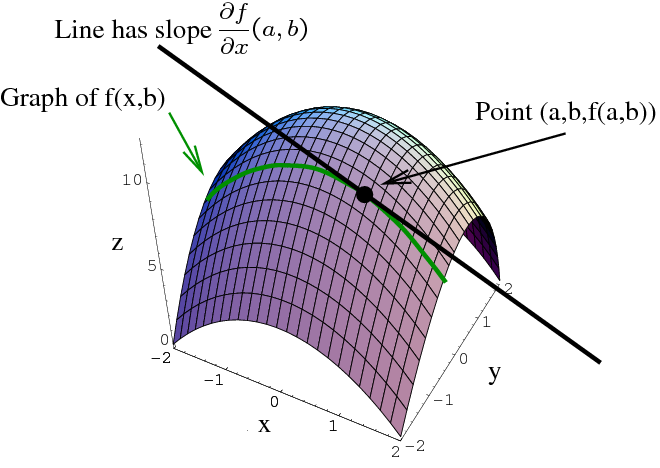
como zero da derivada do erro como função em
.
Antes de começar, recordemo-nos de que, para uma matriz
,
a sua matriz transposta
é a matriz cujas colunas são as linhas de
,
ou, equivalentemente, é a matriz obtida por espelhamento de
ao longo da diagonal. Em particular, para
uma matriz com uma linha ou coluna, um vetor linha respetivamente vetor
coluna,
é o vetor coluna respetivamente linha cujas entradas são as de
.
Aproximação por Projeção
Para exemplificar a derivação da fórmula da regressão linear,
restrinjamos primeiro a
.
Na Regressão Linear, queremos encontrar uma reta que minimize a
distância a pontos
,
…,
no plano. Vimos que a distância entre
a reta (que origina em
)
com inclinação
e
os pontos
é medida pela distância
entre o vetor
e o vetor
,
onde
pomos
,
e
pomos
.
Então, qual é o
que minimize esta distância? Os possíveis valores
formam uma reta (em
,
o plano para
),
e o ponto
da reta que é o mais próximo de
é a projeção
a esta reta; em fórmulas
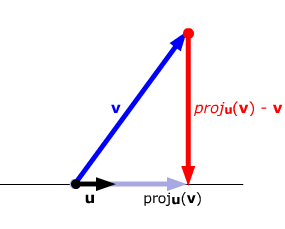
Projeção de um vetor a uma
reta
O ponto
da reta é a projeção de
se, e tão-somente se, a sua diferença
é ortogonal (ou perpendicular, isto é, forma um ângulo
reto) à reta; em fórmulas, se o seu produto escalar é zero,
ou, equivalentemente, se
Obtemos
para o vetor
escalado e transposto de
.
Em geral, para
de dimensão
maior, obtemos
que
é uma matriz cujas
linhas são os vetores
,
…,
com
entradas, e
que
é um vetor (de pesos) com
entradas.
enquanto
permanece um vetor de coluna com
entradas (porque a saída
não mudou).
Os possíveis valores
formam um espaço (de dimensão
em
;
por exemplo, um plano para
).
O ponto
do espaço que é o mais próximo de
é a projeção
de
a este espaço; Obtemos, quando a matriz quadrática
é invertível (o que vale quase sempre porque
,
isto é, tem mais exemplos que parâmetros a especificar), da mesma forma
para o pseudo-inverso
de
.
Aproximação por Derivação
Recordemo-nos de Equação 4.1,
Obtemos
pela aplicação das
igualdades
para toda matriz
e
,
em particular, para
ou
um vetor linha ou coluna
(= matriz com uma única linha ou coluna); além, para dois vetores
e
,
da simetria do seu produto escalar
.
Como a função
em
é (por Equação 4.1) diferençável, podemos
encontrar o seu mínimo no ponto
em que o seu derivado iguala
.
Isto é,
onde
é o gradiente de
,
o vetor linha
cujas entradas são as derivadas
parciais.
Para derivar
observamos primeiro
que
,
porque é constante, não depende de
,
e
que
,
porque é linear em
.
Para calcular
,
abreviemos
,
e observemos que, para a função
,
com
onde usamos a simetria
para
e
.
Se aplicamos estas equações a
,
então obtemos o vetor linha
Logo,
se, e tão-somente se,
se, e tão-somente se,
Computação
Concluímos que o valor mínimo do erro específico
é atingido se, e tão-somente se,
isto é, se e tão-somente se, para
invertível,
onde
é o pseudo-inverso (ou, mais
exatamente, o Moore-Penrose inverso) de
.
Este vetor de pesos
é a única solução ótima.
Esta computação do pseudo-inverso é a parte computacionalmente mais
custosa da regressão linear.
Para acelerar a computação de
,
computa-se uma fatoração
onde
a matriz
é ortonormal, isto é,
,
a matriz cujas únicas entradas diferentes de
são as da diagonal com o valor
,
e
a matriz
triangular.
por exemplo, pelo método de Gram-Schmidt: Denotem
,
,
… as projeções aos vetores
,
,
…, dadas por
Para cada
=
,
,
… o vetor
é ortogonal a
,
…,
.
Logo, os vetores
formam uma base ortonormal.
Isto é,
as colunas da matriz
ortonormal são dadas pelos coeficientes dos vetores
,
,
…, e
a linha número
da matriz
é dada pelos coeficientes
,
…,
;
em particular, a matriz é triangular.
Porém, este método é frágil, isto é, pequenos erro de arredondamento
em resultados intermediários podem levar a grandes erros nos resultados
finais. A este fim, prefere-se o método de Gram-Schmidt
modificado onde
Graças a fatoração
com
,
obtemos
A computação do inverso de uma matriz
triangular em mais rápida do que a de uma matriz geral pois
os coeficientes de uma matriz
inversa se computam pelos determinantes de (sub-)matrizes
de
,
e
o determinante de uma matriz triangular é o produto dos
seus coeficientes diagonais.
Resumo
Concluímos que os passos do algoritmo da
Regressão Linear consistem em:
Dado
,
define a matriz
e o vetor
por
Calcula o pseudo-inverso
da matriz
,
isto é, para
invertível,
Devolve
.
Animação
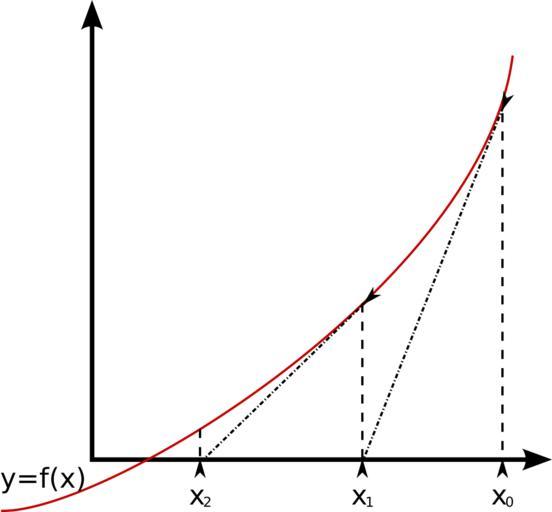
Para ganharmos um intuito como a Regressão Linear calcula a reta que
aproxima melhor os pontos, há uma implementação
online (em JavaScript) da Universidade do Illinois.
4.3 Regressão Logística
A Regressão Logística aplica-se quando
a saída da amostra é binária, isto é,
,
…,
em
,
e
a função alvo é uma medida de probabilidade, isto é, a sua imagem
está no intervalo
(e não em
).
Por exemplo, nas questões,
quão provável é que o cliente quite as contas, ou
quão provável é que o paciente sofra um ataque cardíaco.
Na Regressão Logística,
a entrada
,
e
saída
.
e
as hipóteses
que são medidas de probabilidade obtidas pela composição com certa
função logística.
Por exemplo,
,
onde
mede a pressão sanguínea (ou arterial) do paciente, e
indica se sofreu um ataque cardíaco ou não.
Enquanto o Perceptron decide para cada ponto se é preto
ou branco (isto é, se é ao lado direito ou esquerdo da reta), a
Regressão Logística agrisalha os pontos: quanto mais preto o ponto,
tanto mais provável o evento em questão. Por exemplo, se cada ponto
representa um cliente, que amortize as dívidas.
O grau de griso corresponde à
probabilidade e os pontos aos exemplos observados
Com efeito, a função divina
que queremos conhecer é uma variável aleatória condicional
(binária).
Moralmente,
,
em vez de ser uma função que associa a cada argumento
um único valor
,
é uma variável aleatória condicional (binária) que associa
a cada argumento
uma probabilidade
de cada valor
.
Como
é binário,
basta conhecer
.
Isto é,
determina
;
em outras palavras, o conhecimento de
corresponde ao conhecimento da variável aleatória condicional
.
As nossas hipóteses serão aproximações a
;
logo, por
,
à variável aleatória condicional
.
Função Logística
Para a regressão logística, em que as nossas hipóteses são funções
cujos valores são probabilidades, precisamos de uma função (duas vezes)
diferençável e monótona
.
A necessidade da monotonia da função
baseia-se na concepção que, dado um ponto
,
quanto maior o seu valor
,
tanto mais provável que a decisão seja positiva. (Por exemplo, quanto
maior a pontuação do devedor, mais provável que consiga pagar os
créditos.)
A função logística
A nossa escolha (e a da maioria) é a função
logística (ou função sigmoid) definida por
(Outra escolha popular para
é a função tangente hiperbólica
definida por
.)
Pelo gráfico da função logística, vemos que as duas extremidades se
aproximam dos valores
e
rápido; também, satisfaz a simetria
que nos será útil a seguir.
Log-Odds (= chances
logarítmicas)
Relação à Distribuição
Binomial
A medida de probabilidade, ou distribuição, mais simples é a de uma
variável aleatória binária, isto é, que tem dois possíveis valores
e
.
Chama-se de Bernoulli, e para uma probabilidade fixa
em
é definida por
onde
Expressemo-la pela função exponencial:
Isto é,
é uma distribuição definida pela
exponencial (isto é, faz parte da família exponencial das distribuições)
para um parâmetro
e uma constante
onde
é a função logit (ou log-odds) de
.
A função logística (ou expit) é a função inversa da função
logit; isto é,
Usos
Dificuldade da
Computação da Distribuição Normal
Substituição
Comparação à Distribuição
Normal
Regressão logística (modelo Logbit) em contraste ao modelo probit que
usa a função da densidade da distribuição normal (e regressão de Poisson
que usa a distribuição de Poisson).
As funções de densidade da distribuição normal e logística são
próximas, uma da outra, para uma escolha de parâmetros apropriados a
este fim:
Gráficos de densidade da distribuição
normal e logística
Parâmetros
Como de costume, não explicitamos o parâmetro constante
,
o valor esperado, na hipótese, mas usamos uma saída
em que todos argumento tem a primeira entrada constante igual a
.
Isto é,
.
Hipóteses
As nossas hipóteses são
O valor
no intervalo
corresponde à probabilidade condicional
definida por:
(Por exemplo, dadas as características
do cliente, a probabilidade que
consiga pagar os créditos (o caso
),
ou
falha pagar os créditos (o caso
).)
A nossa função alvo é
a probabilidade (condicional) que
dado
(por exemplo, dadas as características
de um paciente, a probabilidade que ele sofra um ataque cardíaco,
).
Observamos mais exatamente que
(e
)
é uma função densidade de probabilidade condicional
(FDP), ou densidade de uma variável aleatória
contínua condicional, que mede a probabilidade
de uma variável aleatória
tomar um valor fixado
,
em dependência de um valor variável
de uma variável aleatória
.
Erro
A amostra
não revela diretamente
,
a probabilidade que
dado
,
mas a revela indiretamente: os seus valores
,
…,
em
são distribuídos com probabilidade
,
…,
.
Para estimar o erro que uma hipótese
faz em aproximar
sobre
,
usamos o estimador de máxima verossimilhança:
Maximizar a verossimilhança quer dizer determinar os parâmetros
da distribuição
que maximizam a probabilidade
.
Como supomos
,
…,
independente e identicamente distribuídos,
Recordemo-nos de que
corresponde a probabilidade
dada por:
Como
e
,
esta igualdade pode ser simplificada a
Como os valores de
(e logo da função
)
decrescem a zero rápido, é computacionalmente preferível maximizar esta
probabilidade pelo seu logaritmo. Como a função
é monótona decrescente (pelo fator de normalização negativo
),
esta probabilidade é máxima se e tão-somente se
é mínima. Explicitamente, se e
tão-somente se
é mínima. Substituindo
Equação 4.2, obtemos:
substituindo
,
concluímos:
Observamos que
é pequeno se
,
isto é, quanto melhor
classifica
,
…,
,
tanto menor este erro.
Algoritmo
Veremos como maximizar a verossimilhança, isto é, encontrar
a medida que maximiza a probabilidade da nossa amostra.
Equivalentemente, veremos como minimizar
em dependência de
.
Para encontrar um mínimo, usa-se o gradiente de uma função que aponta na
sua direção. Com efeito, para estar num mínimo, tem de ser zero.
Gradiente
Geometricamente, por exemplo, para uma função
de duas variáveis, no ponto
,
a sua primeira derivada parcial
é a inclinação do gráfico no ponto
na direção do
eixo-,
e
a sua segunda derivada parcial
é a inclinação do gráfico no ponto
na direção do
eixo-.
A derivada parcial como tangente na
direção do
eixo-
O gradiente
de uma função
no ponto
é definido pelo vetor linha (e não coluna)
Na nossa situação, onde
para minimizar
,
calculamos o seu gradiente em
,
o vetor linha cujas entradas são as derivadas parciais,
usadano
a Regra da Cadeia aplicada a função
que iguala à sua própria derivada, e
a igualdade
;
note-se que cada parcela
é um vetor linha
em
entradas, e
buscamos
tal que
.
Esta equação não tem uma solução analítica, isto é, não pode
ser expressa por uma fórmula; do lado positivo, a função
é convexa, por isso tem um único mínimo. Logo, nenhum dos métodos corre
risco de convergir a um mínimo local (no lugar do mínimo global).
Para minimizar
,
usamos
ou o método de Newton aplicado à derivada
,
ou o método do máximo declive aplicado à função
.
O método de Newton converge mais rapidamente do que o método do
máximo declive; porém, a sua computação é mais custoso. Em geral, se a
dimensão
não é excecionalmente grande, continua a ser muito mais rápido.
Método de Newton
Estudamos o método de Newton
para funções de uma variável com valores reais, e
para funções de múltiplos argumentos com valores vetoriais (tal que
o número das variáveis da entrada iguale ao da saída).
O uso do método de Newton para minimizar o erro na regressão
logística (= o logaritmo da máxima verossimilhança) chama-se
Fisher scoring.
Para funções reais
Dado uma função derivável
,
o método de Newton aproxima iterativamente um zero de
,
isto é, define
,
,
…em
com
tal que
.
Geometricamente:
Pegamos um ponto (apropriado)
,
olhamos o seu valor
sob
,
e
a tangente em
ao gráfico de
.
Esta tangente intersecta o eixo X em um ponto
.
Olhamos o seu valor
sob
,
e
a tangente em
ao gráfico de
;
e assim por diante.
Moralmente, dado um ponto
,
a tangente
é a reta que aproxima
em
o melhor possível. Por isso, o zero
de
,
que é facilmente computável graças a sua forma simples, aproxima o zero
de
.
Em
,
de novo, a tangente
é a reta que aproxima
em
o melhor; de fato, como
é mais próximo do zero
de
,
a nova tangente
aproxima
melhor do que
em volta de
;
em particular, o
de
é mais próximo do zero
de
do que o zero
de
.
O método de Newton
Como função no argumento
,
na iteração
,
a tangente
em
é definida por
logo, pondo
,
obtemos
Como
,
obtemos
Em outras palavras, o método de Newton
é a iterada aplicação do operador de Newton
definido por
De fato, se
,
então
,
logo
.
A única condição é o encontro de um ponto de partida
tal que a sequência
converge. Esta não é garantida, mas vale a convergência local
quadrática:
Se
é duas vezes diferençável, então pela Fórmula de Taylor
com
para
.
Para
e
,
e porque
,
obtemos
Em particular,
Pondo
(=
,
porque
para um
entre
e
pelo Teorema do Valor Intermediário),
,
e
,
obtemos
Pondo
,
iterativamente
isto é,
Concluímos que se
,
então
quadraticamente. Por exemplo, se
,
então o número de zeros de
,
,
,
… duplica a cada iteração.
Vemos aqui a convergência do método aplicado três vezes à função
com o seu zero
:
Iteração
Zero aproximativo
Erro
0
1
2
3
Para funções de múltiplos
argumentos
Suponhamos que
é uma função de várias variáveis independentes
tal que o número
das variáveis dependentes da entrada iguale ao da saída, isto é,
Isto é,
onde cada função com valores reais
,
…,
depende de
variáveis
,
…,
.
Se
é desta forma, então o seu gradiente
é uma matriz quadrática
Em particular,
é desta forma quando
é o gradiente de outra função
,
isto é,
.
Neste caso, o seu gradiente
é a matriz
das segundas derivadas de
,
a matriz de Hesse de
.
Se
é invertível em
(o que corresponde a
),
então o operador de Newton se torna
O método de Newton continua a convergir rapidíssimo; porém, a
computação da matriz de Hesse de
em cada ponto é computacionalmente custoso (enquanto o método do máximo
declive se contenta com a do mero gradiente). Contudo, se a dimensão
não é excecionalmente grande, continua a ser muito mais rápido.
Método do Máximo Declive
Usamos o método numérico do Gradient Descent, o
Método do Máximo Declive para minimizar
.
Seguindo iterativamente o máximo
declive
Como a função
é convexa, tem um único mínimo (em contraste à imagem). Este pode ser
aproximado como segue:
Pelo gradiente, podemos calcular as derivadas
em todas as direções
(enquanto, até agora, unicamente, nas dos
eixos-,
…,
).
A derivada
da função
em direção
para
é dada por
onde o produto
é o produto escalar entre os
vetores
e
.
Tem-se
onde
é o ângulo entre
e
.
Em particular,
atinge o seu valor máximo, entre todos os vetores de um mesmo
comprimento fixo, por exemplo entre todos os vetores unitários, quando
e
são múltiplos um do outro. Em particular, a derivada em
é máxima, se derivamos em direção de
;
Isto é, geometricamente: O vetor gradiente indica a direção do máximo
aclive (ou declive) cujo grau é medido pelo comprimento do
gradiente!
Computação
Resumimos o algoritmo para a melhor escolha da hipótese
pelo método de Newton aplicado à derivada
,
e
pelo método do máximo declive aplicado à função
.
Pelo Método de Newton
Inicializa o vetor de pesos
.
()
Para
Calcula a matriz de Hesse
em
.
Calcula o novo zero
.
Decide se continuar (com
)
ou terminar a iteração.
()
Devolve o último
(isto é, onde a iteração parou).
onde recordamos
e
Quanto a
(),
à escolha inicial de
,
uma escolha comum para
é
,
ou, para evitar o risco de uma má escolha específica, escolher cada peso
,
…,
independentemente por uma distribuição normal.
Quanto a
(),
um bom critério para a decisão sobre a terminação da iteração, ele é
dado pela satisfação de
um limiar mínimo do erro
(isto é, terminamos quando
for menor do que um certo limiar, ou seja, quando o erro é
suficientemente pequeno)
enquanto
não chegou a
um número máximo
de iterações (como um critério de segurança caso o primeiro critério
acima não se aplique).
Pelo Método do Máximo
Declive
Inicializa o vetor de pesos
(e define a margem de traslado
).
()
Para
Calcula o gradiente
em
.
Põe a direção
.
Atualiza o vetor de pesos
.
Decide se continuar (com
)
ou terminar a iteração.
()
Devolve o último
(isto é, onde a iteração parou).
onde recordamos
Quanto a
(),
às escolhas iniciais de
e
,
uma escolha comum para
é
,
e
uma escolha comum para
é
,
ou, para evitar o risco de uma má escolha específica, escolher cada peso
,
…,
independentemente por uma distribuição normal.
Quanto a
(),
um bom critério para a decisão sobre a terminação da iteração, ele é
dado pela satisfação de
um limiar mínimo do erro
(isto é, terminamos quando
for menor do que um certo limiar, ou seja, quando o erro é
suficientemente pequeno), e
um limiar mínimo da variação do erro
(isto é, terminamos quando
for menor do que um certo limiar, ou seja, as variações do erro são
suficientemente pequenas),
enquanto
não chegou a
um número máximo
de iterações (como um critério de segurança caso os dois critérios acima
não se apliquem).
5 Transformação Linear
Estudaremos como transformar um problema polinomial em um problema
linear, isto é,
de hipóteses que dependem polinomialmente das entradas
a hipóteses que dependem linearmente das entradas.
Aí, podemos aplicar um dos nossos algoritmos lineares, como o
Perceptron, a Regressão Linear ou Logística; depois,
invertemos a linearização para responder ao problema inicial.
Em mais detalhes: Dada uma amostra
,
o algoritmo
escolhe a hipótese
em
que minimiza o erro específico
.
Em todos os algoritmos lineares, isto é, o Perceptron, a
Regressão Linear ou Logística, temos a parametrização
por
onde
é
o
no Perceptron,
a identidade
na Regressão Linear, e
a função logística
na Regressão Logística.
Isto é,
minimiza a função
sobre
;
os pontos da amostra
,
…,
entram como constantes! Portanto, antes de ser dada a
amostra, podemos adaptar a entrada
ao algoritmo linear; isto é, aplicar uma função
que diminua
(onde
é agora um vetor de pesos tal que
seja definido sobre
).
Aplicar uma transformação polinomial para
separar linearmente
5.1 Linearizar Elipses em
torno da origem
Usamos o Perceptron sobre o plano
para separar os pontos do tipo
,
positivos, dos pontos do tipo
,
negativos, de uma amostra
,
…,
por uma reta. Suponhamos que a amostra não é linearmente separável, mas
que todos os pontos positivos estão cercados por um círculo.
Pontos Cercados
Um círculo no plano com raio
é dado pela equação
isto é, dado por uma equação polinomial
quadrática, e a função
separa entre os pontos positivos e
negativos. Se escrevemos
onde
então
é uma função linear (ignorando o sinal)
em
com (o vetor de) pesos
.
Explicitamente,
A função
é chamada a transformação de características. A transformação
leva toda função linear
sobre o espaço transformado
por
a uma função, não necessariamente
linear,
sobre o espaço original.
Ida e volta ao espaço
transformado
Se
anula o erro específico,
,
então igualmente
o anula,
.
Se
é estabelecida antes de ser dada a amostra, então
onde
é o espaço das hipóteses
e
é o espaço das hipóteses sobre
.
Vale somente a desigualdade, mas não necessariamente a igualdade, isto
é, não necessariamente toda função em
pode ser obtida por pré-composição de uma função em
com
.
Por exemplo, se
é a transformação acima e o algoritmo é o Perceptron,
então
Com efeito, a mesma configuração de
pontos como em Figura 3.1 é também
linearmente inseparável por uma elipse (que é centrada na origem).
Observação. A aplicação
tem de ser escolhida antes de ser dada a amostra; isto é, não
pela avaliação dos dados, mas pela nossa compreensão do problema. Caso
contrário, estamos efetivamente aumentando
e assim
.
5.2 Generalização da
Transformação
Restamos no plano, isto é,
.
Enquanto a dimensão de
é igualmente
,
somente podemos separar pontos por elipses centradas na origem do plano,
o ponto
.
Contudo, para obter todas as curvas quadráticas, precisamos aumentar a
dimensão de
a
para aplicar
(Descontamos a primeira coordenada pela
sua entrada fixa
.)
Por esta transformação de características, podemos, por exemplo,
trasladar o centro das elipses da origem
a qualquer ponto no plano.
Mais geralmente, podemos considerar a transformação de
características para curvas cúbicas, enfim, para polinômios de grau
qualquer. Uma tal transformação é chamada a transformação polinomial
de grau
.
Mas, cautela! Agora
tornou se
.
Além de aumentar o esforço computacional do algoritmo, aumenta a
dimensão de Vapnik-Chervonenkis, por exemplo, para o
Perceptron de
à
.
Surge outra vez o dilema entre o erro geral e o erro específico:
Se aumenta
,
então
diminui
,
mas
aumenta
e então
.
Se diminui
,
então
aumenta
,
mas
diminui
e então
.
5.3 O Artifício do Núcleo
Dada uma transformação
do espaço vetorial
de dimensão menor ao espaço vetorial (de re-descrição)
de dimensão maior. O artifício no Artifício do Núcleo
consiste em calcular o núcleo (= produto escalar transformado)
sobre
diretamente a partir de
,
sem conhecer
nem
!
Como
é de dimensão menor, fica computacionalmente mais econômico.
Em vez de definir a transformação
,
o produto
é definido diretamente e a existência de
é implícita; se
satisfaz uma certa positividade, ela é assegurada pelo
Teorema de Mercer.
Com efeito, recordamos que o objetivo final num problema de
aprendizado é a escolha da melhor hipótese
em
pelo algoritmo
a partir da amostra
.
Para nós, melhor quer dizer minimizar certo erro
sobre a amostra
.
Em todos os algoritmos lineares em Seção 4, identificamos
com um vetor de pesos
e obtivemos
no Perceptron,
,
na Regressão Linear,
,
no Perceptron,
.
A observação que importa é que em todos os três casos, para minimizar
o erro
,
basta saber o produto escalar
!
Em particular, se
é transformado por uma aplicação
,
é suficiente saber o valor do produto escalar transformado
para todos os
em
;
portanto, é desnecessário conhecer
em si! Na prática, em vez de definir
,
é diretamente definido o produto escalar transformado
;
o Teorema de Mercer define
implicitamente.
Aumentar a dimensão por uma transformação
polinómial para poder separar linearmente
Princípio
Em cada um dos nossos algoritmos lineares em Seção 4, o erro específico
dependia no final somente de um produto escalar. Após uma transformação
linear
,
este toma a forma:
Si o espaço vetorial
é de alta dimensão, então a computação deste produto fica impraticável.
A ideia é então substituir este produto por uma função
da forma
Teorema de Mercer
O Teorema de Mercer (James Mercer, matemático inglês do século
)
mostra que uma função contínua, simétrica e semi-definida
pode ser expressa por um produto escalar em um espaço vetorial de grande
dimensão.
Mais exatamente, se o domínio
de
é um espaço mensurável, e se
é semi-definida, isto é,
para qualquer conjunto finito
no domínio
e conjunto finito
no contra-domínio
(tipicamente
),
então existe uma função
onde
é um espaço vetorial pré-hilbertiano (provavelmente de maior dimensão)
tal que:
Vantagem
Assim, o produto escalar em um espaço vetorial de grande dimensão é
substituído por um núcleo que é mais facilmente calculável. Esta é uma
maneira econômica de transformar um classificador linear em um
classificador não-linear. Pelo núcleo, a transformação
nem precisa ser explicitada. Desta maneira, mesmo se o espaço vetorial
é de dimensão infinita, o produto escalar transformado, o núcleo,
permanece calculável como exemplificado pelo núcleo gaussiano
radial-simétrica:
Ele é muito usado para
SVMs.
Outro exemplo, popular no processamento automático de linguagem
natural, é o núcleo polinomial
para um inteiro
.
Aplicações
O artifício do núcleo foi apresentada pela primeira vez em
por Aizerman, mas teve pouca repercussão. Ele pegou pelo artigo “A
Training Algorithm for Optimal Margin Classifiers” por Boser et
al. (publicado em
)
que fundou a teoria dos Support Vector Machines. Desde
então, aplica-se em algoritmos de aprendizado de máquina como
Support Vector Machines,
análise de componentes principais, e
análise da discriminante linear.
6 Redes Neurais
Recordemo-nos de que, formalmente, em um problema de aprendizado,
temos
a entrada
,
a saída
,
os dados ou a amostra
(= um conjunto finito em
sobre o qual a função alvo é conhecida, isto é,
,
…,
são conhecidos, e
a função alvo (ou função de regressão ou
classificadora)
(= a função ótima, que sempre acerta, a ser aproximada; chamamo-la
também de função divina para exprimir que existe e é
aproximável com certa probabilidade, mas inatingível)
e o método de aprendizado:
as hipóteses
(= um conjunto de funções que aproximam
),
uma medida de erro
que mede a diferença entre os valores da hipótese e os da função alvo,
e
um algoritmo
que escolhe uma função
em
que aproxima”
“o melhor”, em particular, minimiza
sobre
.
Uma rede neural (feed-forward ou sem
realimentação) consiste em neurónios agrupados em camadas
onde a entrada de cada neurónio são as saídas de todos os neurónios da
camada anterior.
A primeira camada é a da entrada, e a última a da
saída; as outras chamam se camadas
ocultas.
Uma rede neural de uma única camada
oculta com três neurónios.
Se a rede neural tem múltiplas camadas ocultas, então é uma rede
neural profunda, as quais são usadas no Deep
Learning, no aprendizado profundo.
Cada neurónio é uma função
que é uma composição
de
uma função afim,
(cujo gráfico é uma reta), e
uma função de ativação
que não é afim.
6.1 Funções de Ativação
Para a última camada (para tarefas de classificação) usa-se
frequentemente uma Função de Ativação Softmax definida por:
onde
é um vetor de ( K ) dimensões e ( i ) é o índice do elemento.
Ela normaliza a saída de um vetor de valores para uma distribuição de
probabilidade.
Função de
Ativação ReLU (Unidade Linear Retificada)
Definida por:
Não-saturante, o que reduz o problema de gradientes que desaparecem
(vanishing gradients) para valores positivos de ( x ).
Eficiência computacional devido à sua simplicidade.
Função de Ativação Leaky
ReLU
Definida por:
onde
é um pequeno coeficiente positivo.
Visa resolver o problema de neurônios “mortos” em ReLU, permitindo
um pequeno gradiente quando ( x ) é negativo.
Mantém as vantagens computacionais da ReLU.
Função de Ativação Sigmoide
Definida por:
Mapeia a entrada para um intervalo entre 0 e 1.
Suave e diferenciável em todo o seu domínio.
Suscetível ao problema de gradientes que desaparecem para entradas
com grande magnitude.
Função de Ativação
Tangente Hiperbólica (tanh)
Definida por:
Mapeia a entrada para um intervalo entre -1 e 1.
Suave e diferenciável em todo o seu domínio.
Também pode sofrer do problema de gradientes que desaparecem, embora
em menor grau que a sigmoide.
6.2 Rede neural de camada
única
Para entender esses diagramas, vamos começar o curso com redes
neurais de camada única: Uma rede Perceptron que tem uma única camada
oculta e uma única saída consiste em um único neurônio.
Um neurônio descreve uma classe de problemas de
aprendizado cujas hipóteses são caracterizadas pela composição de uma
função de saída não linear com uma função afim; essa classe inclui,
entre outros métodos,
regressão linear,
o Perceptron ou discriminador linear para classificação
binária,
multiClass-Perceptron para classificação finita, ou seja, entre um
número finito de classes,
para regressão logística multinomial (ou regressão softmax),
consiste em matrizes finitas
cujas entradas não negativas somam
.
uma rede neural com um único
neurônio](./images/single-perceptron.png)
O método de aprendizado:
cada hipótese é a composição
de
uma função de saída não linear, geralmente não constante,
limitada, monotonamente crescente e contínua. Os exemplos são
para regressão linear, a identidade
,
para o Perceptron, o sinal
se
e
caso contrário,
para o MultiClass-Perceptron,
,
ou seja, o argumento
com
,
para regressão logística
a função logística
definida por
,
ou
a função tangente hiperbólica
definida por
.
para a regressão logística multinomial, a função
uma função final
,
ou seja, uma função que é definida por determinados
coeficientes
,
,
… e por um determinado limiar
:
Se a função tiver um único argumento,
ela será afim se, e somente se, seu gráfico for uma linha reta. O peso
corresponde ao grau de inclinação (também chamado de coeficiente de
ângulo) e o limite à altura em que o gráfico cruza a
ordenada.
uma medida de erro
que mede a diferença entre os valores da hipótese e os da
função-alvo:
para regressão linear, a distância ao quadrado,
para o Perceptron (e o MultiClass-Perceptron), a contagem do número
de valores diferentes entre
e
,
para regressão logística (e multinomial), o log-likelihod, a máxima
verossimilhança.
um algoritmo
que escolhe uma função
em
que “aproxima
da melhor forma”, ou seja, minimiza
em
;
para saídas contínuas, como (um intervalo em)
,
o método (estocástico) de inclinação máxima é normalmente usado, mas o
método de Newton também é possível como alternativa.
6.3
Teorema de aproximação universal para redes de camada única
O Teorema de Aproximação Universal para Funções de Ativação Não
Polinomiais afirma que uma rede neural com uma única camada oculta pode
aproximar qualquer função contínua em um domínio compacto,
independentemente da dimensão dos espaços de entrada e saída, com
qualquer grau de precisão desejado, desde que a função de ativação seja
contínua e não polinomial e que possamos ter tantos neurônios na camada
oculta quantos forem necessários para atingir a precisão desejada.
Teorema de aproximação universal para funções de ativação não
polinomiais: Seja
seja uma função contínua. Então,
não é polinomial se e somente se, para toda função
definida em um conjunto compacto
com valores em
para quaisquer
e
,
e para todo
,
existirem
uma matriz
e um vetor
,
uma matriz
,
para algum
,
de modo que
é definida por
satisfaz
Interpretação
O Teorema da Aproximação Universal oferece uma garantia teórica de
que as redes neurais têm o potencial de modelar qualquer função contínua
com qualquer nível de precisão, desde que haja uma função de ativação
não polinomial adequada e um número suficientemente grande de neurônios
na camada oculta.
Considere uma função
que desejamos aproximar. Essa função recebe um vetor de um espaço de
dimensões e produz um vetor em um espaço de
dimensões. O espaço do qual as entradas são retiradas é compacto, o que
significa que é limitado e contém todos os seus pontos-limite, o que é
uma situação comum em aplicações práticas.
A rede neural em questão, representada por
,
é um modelo matemático que tenta imitar o comportamento de
.
A rede faz isso transformando o vetor de entrada
usando uma combinação de operações lineares e não lineares. A parte
linear envolve a multiplicação de
por uma matriz
e a adição de um vetor
,
enquanto a parte não linear é tratada com a aplicação da função de
ativação
ao resultado.
A dimensão
representa o número de neurônios na camada oculta da rede neural. Cada
neurônio contribui para a capacidade da rede de capturar um aspecto
diferente da função
.
As matrizes
e
e o vetor
são os parâmetros da rede neural que são ajustados durante o processo de
treinamento para minimizar a diferença entre a saída da rede e os
valores reais da função.
A dimensão
é crucial porque determina a capacidade da rede neural de aproximar
funções complexas. Um
maior significa mais neurônios na camada oculta, o que, por sua vez,
significa mais flexibilidade para a rede neural ajustar a função
.
Entretanto, nem sempre o simples fato de aumentar
produzirá melhores aproximações; os parâmetros da rede também devem ser
ajustados de forma otimizada, geralmente por meio de treinamento.
Teorema
de aproximação universal de Leshno para redes neurais feedforward de
camada única
Seja
seja uma função de ativação contínua, não constante e não polinomial.
Considere
como um conjunto compacto. Nosso objetivo é mostrar que o conjunto de
funções da forma
onde
,
,
e
,
é denso em
,
o espaço de funções contínuas em
com a norma do supremo.
Etapa
1: não densidade das funções de ativação polinomial
Seja
.
Suponha que
seja um polinômio de grau
.
Então,
também é um polinômio de grau
para todo
e
.
O conjunto
de polinômios algébricos de grau no máximo
é exatamente o conjunto de funções que podem ser representadas por esse
.
Como
é um subconjunto adequado de
,
ele não é denso em
.
Etapa
2: a densidade em
implica a densidade em
Suponha que
não seja um polinômio. Se
é denso em
,
então
é denso em
,
uma vez que o espaço
abrangido por funções da forma
,
em que
e
,
é denso em
.
Etapa
3: as funções de ativação suave são densas em
Se
,
o conjunto de todas as funções com derivadas de todas as ordens, então
é denso em
.
Para isso, basta mostrar que
contém todos os monômios pelo Teorema de Weierstrass.
Para todo
e
em
,
o quociente da diferença (de funções)
está em
.
Como
é diferenciável e
é completo, a primeira derivada
de
com relação a
em
,
como limite desses quocientes de diferença, está em
.
Como
não é constante, há
de modo que
.
Assim, descobrimos que
está em
.
Iterativamente,
em
.
Como
não é polinomial, existe para cada
algum
tal que
.
Portanto, todo monômio
está em
.
Observação: Neste ponto, já provamos o Teorema de
Aproximação Universal para funções de ativação sigmoidais clássicas
(suaves).
Infelizmente, a função de ativação mais comum atualmente, a ReLU, não
é suave em
;
portanto, é necessário trabalho adicional para uma função de ativação
meramente contínua:
Etapa 4:
Aproximação de funções de suporte compactas
Para
,
o espaço de funções suaves com suporte compacto,
,
em que
denota convolução.
Isso é comprovado pela aproximação da integral da convolução usando
uma soma de Riemann, que converge uniformemente para
em qualquer intervalo compacto.
Etapa
5: densidade em
para convolução não polinomial
Se
não for um polinômio para algum
,
então
é denso em
.
Isso decorre das etapas 3 e 4, já que
pode ser demonstrado como sendo suave.
Neste ponto, resta mostrar que isso só pode ocorrer se
for polinomial:
Etapa
6: a convolução polinomial implica a ativação polinomial
Se
for um polinômio para todos os
,
então existe um
de modo que
seja um polinômio de grau no máximo
para todos os
.
Etapa
7: a convolução polinomial implica a ativação polinomial
Se
é um polinômio de grau no máximo
para todos os
,
então
é um polinômio de grau no máximo
(em quase todos os lugares).
Conclusão
O conjunto de combinações lineares finitas de translações e
dilatações de
é denso em
.
Isso significa que, para qualquer função contínua
e qualquer
,
existe uma função
tal que
,
em que
denota a norma do supremo.
6.4 Rede neural de múltiplas
camadas
Uma rede neural feedforward consiste em várias camadas:
a camada de entrada,
camadas ocultas e
a camada de saída.
uma rede neural com duas camadas
ocultas](./images/multilayer-perceptron.png)
Hipótese
Cada camada é uma função de várias entradas e saídas
da seguinte forma:
A camada de entrada é a identidade,
cada camada oculta é uma matriz
de neurônios. Cada neurônio
é a composição
de
uma função de ativação
fixa, ou seja, a mesma para todos os neurônios em todas as
camadas ocultas (mas não para as da camada de saída). Por
exemplo, a função tangente hiperbólica
definida por
.
uma função afim
que é definida por certos coeficientes
,
,
… e por um certo limiar
,
ou seja
A camada de saída é um neurônio em que a função de ativação é uma
função de saída que pode ter uma forma diferente, por exemplo,
para regressão linear, a identidade
,
para o Perceptron, o sinal
se
e
caso contrário,
para o MultiClass-Perceptron,
,
ou seja, o argumento
com
,
para regressão logística
a função logística
definida por
,
ou
a função tangente hiperbólica
definida por
.
para regressão logística multinomial, a função `softmax
Se todos os neurônios da mesma camada tiverem o mesmo número de
entradas que os neurônios da camada anterior, então a rede perceptron é
totalmente conectada;
A função (de hipótese
que se aproxima da função divina) de uma rede neural de
propagação direta é a composição sucessiva dos múltiplos da
função para cada camada
6.5
Teorema de aproximação universal para redes ReLU limitadas por
largura
Lembremos que a função de ativação da ReLU (Unidade Linear
Retificada) é definida como
.
O Teorema de Aproximação Universal para Redes ReLU Limitadas por
Largura estende o Teorema de Aproximação Universal (UAT) clássico para
redes ReLU limitadas por largura.
Teorema: Para qualquer função integrável de Lebesgue
e para qualquer precisão desejada
,
existe uma rede neural ReLU totalmente conectada
com uma largura
que pode aproximar
com um erro de
de
.
A função
representada pela rede
satisfaz:
Esse teorema mostra que as redes com uma largura limitada,
especificamente não mais do que quatro unidades maiores do que a
dimensão de entrada, ainda podem aproximar qualquer função integrável de
Lebesgue arbitrariamente bem no sentido de
em todo o espaço euclidiano.
Comparação com o Teorema de
Leshno
O UAT com limite de profundidade de Leshno mostrou que as redes
feedforward multicamadas com uma função de ativação não polinomial, como
a função ReLU, são densas no espaço de funções contínuas em subconjuntos
compactos de
com relação à norma
.
Esse teorema com limite de largura difere do teorema de Leshno em
vários aspectos importantes:
Espaço funcional: O teorema de Leshno considera
funções contínuas em domínios compactos, enquanto o teorema de limite de
largura considera funções integráveis de Lebesgue em todo o espaço
euclidiano.
Norma: O teorema de Leshno usa a norma
,
que mede o erro máximo entre a função de destino e a função de
aproximação. O teorema de limite de largura usa a norma
,
que mede o erro médio em todo o domínio.
Arquitetura de rede: O teorema de Leshno não
impõe restrições à largura da rede, permitindo que ela cresça conforme
necessário. O teorema da largura limitada, por outro lado, restringe a
rede a ter uma largura não superior a
.
Domínio de aproximação: O teorema de Leshno
exige que o domínio seja compacto, o que não é o caso do teorema da
largura limitada.
Função de ativação: Ambos os teoremas consideram
redes com funções de ativação ReLU, mas as implicações de seus
resultados são diferentes devido a outras condições diferentes.
Prova (esboço)
Para qualquer função integrável de Lebesgue
e qualquer precisão de aproximação predefinida
,
construímos explicitamente uma rede ReLU de largura
para que ela possa aproximar a função com a precisão determinada (dentro
de um erro de
de
).
A rede é uma concatenação de uma série de blocos. Cada bloco satisfaz as
seguintes propriedades:
É uma rede ReLU com
profundidade-
e
largura-.
Ele pode aproximar qualquer função integrável de Lebesgue que seja
uniformemente zero fora de um cubo com comprimento
com alta precisão;
Pode armazenar o resultado do bloco anterior, ou seja, a aproximação
de outras funções integráveis de Lebesgue em cubos diferentes;
Ele pode somar sua aproximação atual e a memória das aproximações
anteriores.
Etapa 1: Truncamento e
decomposição
Dado
e
,
selecione
de modo que a integral de
fora do cubo
seja menor que
.
Defina
e
como as partes positivas e negativas de
truncadas no cubo
.
Em seguida, decomponha
e
em funções simples que são somas de funções indicadoras de cubos
dentro de
.
Essa decomposição pode ser feita de modo que o erro de
seja menor que
:
O índice
assume dois valores, 1 e 2, correspondentes às partes positivas e
negativas da função
truncada no cubo
.
Especificamente:
corresponde a
,
que representa a parte positiva de
dentro do cubo
.
corresponde a
,
que representa a parte negativa de
dentro do cubo
.
O índice
enumera o conjunto finito de cubos menores de dimensão
que cobrem a região onde
é diferente de zero. Esses cubos são usados para construir funções
simples que aproximam
por uma soma finita de funções indicadoras ponderadas. O processo é o
seguinte:
Para cada
,
considere a região
sob o gráfico de
sobre o cubo
.
Essa região é mensurável, e nosso objetivo é cobri-la com um número
finito de cubos
-dimensionais
.
Usando as propriedades da medida de Lebesgue, podemos encontrar uma
cobertura de
por um número finito de cubos
-dimensionais
de modo que a medida da diferença simétrica entre
e a união desses cubos seja pequena (menor que
para cada
).
O índice
vai de 1 a
,
onde
é o número de cubos
na cobertura para
.
Etapa 2:
Construção de unidades únicas de ReLU (SRUs)
Para cada cubo
,
construímos uma Single ReLU Unit (SRU) que aproxima sua função
indicadora. A SRU é uma rede ReLU rasa com largura de
e profundidade de
.
Ele aproxima a função indicadora do cubo de dimensão
manipulando o espaço de entrada por meio de uma série de transformações
afins e ativações ReLU. A saída final é uma função que se assemelha
muito à função indicadora dentro de uma margem de erro controlada.
Forma do SRU
Uma Single ReLU Unit (SRU) é uma sub-rede projetada para aproximar a
função indicadora de um cubo de dimensão
.
A SRU tem uma largura de
neurônios e uma profundidade de 3 camadas. A arquitetura da SRU é
adaptada para manipular o espaço de entrada de forma a produzir um valor
próximo a 1 dentro do cubo de destino e transições para 0 fora do
cubo.
Aproximação da função
indicadora
Considere um cubo
-dimensional
e sua função indicadora
definida por ser igual a
em
e
fora dele. Para aproximar
usando uma SRU, construímos uma função linear por partes que imita esse
comportamento usando a função de ativação ReLU, definida como
.
Camada 1: Transformação de
entrada
A primeira camada do SRU consiste em
neurônios que realizam uma transformação afim em cada coordenada de
entrada
para preparar a ativação ReLU. Para cada dimensão
,
temos dois neurônios:
Um neurônio calcula
,
que é ativado quando
é maior que
.
Outro neurônio calcula
,
que é ativado quando
é menor que
.
Camada 2: Intersecção de
meios-espaços
A segunda camada pega as saídas da primeira camada e as combina para
formar a interseção dos meios-espaços correspondentes ao cubo. Cada
neurônio dessa camada recebe entradas de dois neurônios da camada
anterior correspondentes à mesma dimensão. A saída de cada neurônio
nessa camada é o mínimo das duas entradas, o que é obtido pela ativação
ReLU:
Isso garante que o neurônio só seja ativado quando
estiver entre
e
.
Camada 3: Agregação e saída
final
A terceira camada agrega os outputs da segunda camada para garantir
que todas as dimensões estejam dentro do cubo. Isso é feito somando os
resultados da segunda camada e subtraindo uma pequena margem
para garantir uma desigualdade estrita:
A subtração de
garante que o resultado seja 1 somente se todas as dimensões
estiverem dentro dos limites do cubo. A saída será 0 se alguma dimensão
estiver fora do cubo.
Qualidade da aproximação
O SRU aproxima a função indicadora
produzindo uma forma hipertrapezoidal dentro do cubo
.
Ao ajustar a margem
,
podemos controlar a inclinação da transição de 1 para 0 nos limites do
cubo. Quanto menor for o
,
mais próxima será a aproximação da verdadeira função indicadora. No
entanto, existe uma compensação entre a inclinação da transição e a
suavidade da aproximação.
Ao integrar a diferença absoluta entre a função indicadora
e a saída da SRU em todo o espaço, podemos garantir que o erro seja
menor que um limite especificado. Isso é obtido selecionando um
adequado que equilibre a qualidade da aproximação com o nível de
precisão desejado.
Etapa 3: Montagem da rede
A rede completa
é construída pela concatenação de várias SRUs (Single ReLU Units) para
todos os cubos
e camadas adicionais para combinar suas saídas. Cada SRU é responsável
pela aproximação da função indicadora de um cubo
,
e a rede deve somar essas aproximações para formar a aproximação geral
de
.
A rede
foi projetada para aproximar a parte positiva
e a parte negativa
da função
separadamente e, em seguida, combinar essas aproximações para produzir a
aproximação final de
.
Concatenação de SRUs
Cada SRU é uma sub-rede de profundidade 3 que aproxima a função
indicadora de um cubo
.
A rede
concatena essas SRUs para todos os cubos
que foram identificados na decomposição de
e
.
A saída de cada SRU é uma função
que aproxima a função indicadora correspondente
.
Armazenamento de
aproximações de SRU
A rede
contém camadas que armazenam as saídas das SRUs. Essas camadas são
projetadas para reter as informações das SRUs anteriores enquanto
processam a SRU atual. Isso é obtido por meio de um conjunto de
neurônios que atuam como “unidades de memória”, que simplesmente passam
os valores de uma camada para a seguinte sem nenhuma modificação. Esses
neurônios garantem que as aproximações de todas as SRUs estejam
disponíveis para a soma final.
Soma de aproximações
Depois que as SRUs tiverem calculado suas respectivas aproximações, a
rede precisará somar essas aproximações para formar a aproximação geral
de
e
.
Isso é feito por camadas adicionais que combinam as saídas das SRUs.
Especificamente, a rede tem neurônios dedicados a somar as saídas das
SRUs correspondentes a
e, separadamente, as saídas das SRUs correspondentes a
.
Para cada parte
,
a soma é calculada da seguinte forma:
em que
é o comprimento do
-ésimo
lado do cubo
,
que atua como um peso para a aproximação
.
Insuficiência
de redes com profundidade limitada
O Teorema 1 implica que há um ponto de ruptura para o poder
expressivo das redes ReLU à medida que a largura da rede varia em
,
a dimensão de entrada. Não é difícil perceber que, se a largura for
muito menor que
,
o poder expressivo da rede deve ser muito fraco. Formalmente, temos os
dois resultados a seguir:
Teorema (Falha da aproximação universal no espaço
euclidiano). Para qualquer função integrável de Lebesgue
que satisfaça que
seja um conjunto de medidas positivas na medida de Lebesgue e qualquer
função
representada por uma rede ReLU totalmente conectada
com largura de no máximo
:
Esse teorema diz que, mesmo quando a
largura é igual a
,
a capacidade de aproximação da rede ReLU ainda é fraca, pelo menos no
espaço euclidiano
.
No entanto, se restringirmos a função em um conjunto limitado, ainda
poderemos provar o seguinte teorema:
Teorema (Falha da aproximação universal em um domínio
compacto). Para qualquer função contínua
que não seja constante em nenhuma direção, existe um
universal de modo que, para qualquer função
representada por uma rede ReLU totalmente conectada com largura menor
que
,
a distância
entre
e
é de pelo menos
:
Ou seja, para qualquer função contínua
,
que varia em todas as direções, há um limite inferior
na distância
entre
e qualquer aproximação
que possa ser obtida por uma rede ReLU totalmente conectada com menos
neurônios em sua(s) camada(s) oculta(s) do que a dimensionalidade do
espaço de entrada.
Prova (esboço)
Considere uma rede ReLU totalmente conectada
com entrada
e valores do nó da primeira camada
onde
.
A saída dos nós da primeira camada é dada por:
para
e
,
sendo
e
os parâmetros da rede.
Etapa 1:
Existência de uma direção que não afeta
Como
,
existe um vetor diferente de zero
ortogonal à extensão dos vetores formados pelas transformações afins da
primeira camada. (Ou seja, ele está no núcleo da parte linear da
transformação afim) Ou seja, mover-se ao longo de
não afeta a saída da primeira camada e, portanto,
é constante ao longo de
.
Etapa 2:
Estabelecimento do limite inferior
Demonstramos que, para qualquer função contínua
e um vetor unitário fixo
,
existe um
positivo de modo que, para todas as funções contínuas
constantes ao longo de
,
a distância
entre
e
é de pelo menos
:
Deixe
denotar a bola aberta de raio
centrada em
em
Como
não é constante em nenhuma direção e é contínua, existem dois pontos
e
ao longo de
,
um raio
e uma constante
de modo que, para todos os
e
,
temos
.
Temos
,
porque
é constante ao longo da direção de
para
.
Usando a desigualdade triangular, obtemos:
já que
e, portanto,
em
.
Integrando ambos os lados sobre a bola
com relação a
,
obtemos:
em que
denota a medida de Lebesgue de
(e
).
Portanto, escolhendo
,
temos
Etapa 3:
Argumento de continuidade e compacidade
Como
é positivo e contínuo como função de
(devido à continuidade de
e
),
e como o conjunto de todos os vetores unitários
forma um conjunto compacto (a superfície da esfera unitária em
),
há um limite inferior uniforme
em todos os vetores unitários
.
6.6 Largura
versus profundidade das redes neurais
Em Telgarsky (2016), Telgarsky
mostrou que existem funções computáveis por uma rede ReLU profunda com
um número polinomial de unidades que não podem ser aproximadas por
nenhuma rede superficial (uma rede com apenas uma camada oculta), a
menos que ela tenha exponencialmente muitas unidades. O resultado
principal implica que, para qualquer número inteiro positivo
,
existe uma função
que é calculada por uma rede neural com
camadas e
nós no total, de modo que nenhuma rede mais rasa com no máximo
camadas e menos de
nós pode aproximar
dentro de uma distância
de
sobre o cubo unitário
.
Ideia de prova
A prova constrói uma função dente de serra específica usando uma rede
profunda com ativações ReLU. Essa função oscila rapidamente e tem muitos
“dentes”, que são essencialmente peças lineares com inclinações
alternadas. A construção é tal que cada camada adicional na rede dobra o
número de peças lineares, levando a um aumento exponencial no número de
oscilações com relação à profundidade da rede.
Para aproximar essa função com uma rede rasa, seria necessária uma
peça linear separada para cada dente da função dente de serra. Como o
número de dentes é exponencial na profundidade da rede profunda, uma
rede rasa exigiria um número exponencial de unidades para atingir um
nível semelhante de aproximação.
A prova aproveita a estrutura de composição das redes profundas, em
que cada camada pode se basear nas transformações das camadas
anteriores, permitindo que funções complexas sejam representadas de
forma mais compacta do que em redes rasas. Esse resultado destaca os
benefícios da profundidade nas redes neurais, mostrando que a
profundidade pode levar a um aumento significativo no poder de
representação.
6.7 O método do Máximo Declive
Em vez de um limiar, para facilitar a notação, suponhamos que exista
uma entrada adicional igual a
:
Convenção. Para facilitar a notação, suponhamos de
agora em diante que cada camada tenha como entrada um fator igual a
,
isto é,
cujas ênuplas numeremos por
.
Desta maneira, o limiar
corresponde ao peso
,
e não necessita mais ser considerado separadamente.
Medida de Erro
Com a saída não discreta, gostaríamos de tomar em conta o tamanho da
diferença
em cada ponto
;
usaremos a diferença quadrática a este fim, isto é
O método do Máximo Declive
O algoritmo usa o método do Máximo Declive para minimizar o
erro quadrático. Ele busca um mínimo local por um ponto no qual a
derivada, o gradiente, da medida de erro
como função em
é zero, isto é, todas as derivadas parciais ao longo dos pesos dos
neurónios esvaem-se.
Mais exatamente, recordemo-nos de que cada camada
tem múltiplos neurónios
,
e cada neurónio atribui a cada entrada
(= a saída do neurónio
da camada precedente) um peso
.
Para minimizar
como função dos pesos
,
isto é, para calcular o gradiente
,
dado pelas derivadas parciais, e aproximar o valor zero:
Inicializa o vetor de pesos
(e define a margem de traslado
).
()
Para
Calcula o gradiente
em
.
Põe a direção
.
Atualiza o vetor de pesos
.
Decide se continuar (com
)
ou terminar a iteração.
()
Devolve o último
(isto é, onde a iteração parou).
Quanto a
(),
às escolhas iniciais de
e
,
uma escolha comum para
é
,
e
uma escolha comum para
é
,
ou, para evitar o risco de uma má escolha específica, escolher cada peso
,
…,
independentemente por uma distribuição normal.
Quanto a
(),
um bom critério para a decisão sobre a terminação da iteração, ele é
dado pela satisfação de
um limiar mínimo do erro
(isto é, terminamos quando
for menor do que um certo limiar, ou seja, quando o erro é
suficientemente pequeno), e
um limiar mínimo da variação do erro
(isto é, terminamos quando
for menor do que um certo limiar, ou seja, as variações do erro são
suficientemente pequenas),
enquanto
não chegou a
um número máximo
de iterações (como um critério de segurança caso os dois critérios acima
não se apliquem).
6.8 Vetorização
Para acelerar a computação, as saídas da função afim (de múltiplas
saídas) de cada camada é calculada por matrizes:
Saída
Em vez de calcular separadamente, para cada neurónio de uma camada,
e
é mais eficiente calcular
e
onde
,
e
é a matriz com as linhas
,
,
…
Amostra
Para vetorizar, simultanear, a computação sobre múltiplas entradas,
isto é, sobre todos os exemplos
,
,
… da amostra, pomos
e calculamos
6.9
Auto-diferenciação inversa pela Regra da Cadeia
Dada uma rede neural de propagação à frente cuja medida de erro é o
erro quadrático. Dada uma amostra
,
…,
com valores
,
…,
,
(a metade d’) o erro quadrático é
(O fator de normalização
simplificará a fórmula da derivada a seguir.) A rede é parametrizada
pelos pesos
dos neurónios. Queremos minimizar
em dependência de
.
Para minimizar
em dependência de
,
calculemos as derivada parciais
para, idealmente, encontrar um zero
comum entre elas. Como
e
podemos primeiro calcular
para cada exemplo
,
…,
e cada neurónio
,
…,
da saída e depois somar os resultados. Logo, para simplificar as
fórmulas, suponhamos um único exemplo
e um único neurónio de saída, isto é,
e
tais que
Pela Regra da Cadeia,
onde
é a função afim do neurónio
da camada
cujo valor em
é computado por
Para o neurónio
na camada
,
denotemos
a sua função afim por
,
a sua função não-afim por
,
a sua função composta por
,
e
o fator ao lado esquerdo do produto em
,
o erro da saída, por
Para calcular o fator ao lado direito do produto em
,
observemos que pela Regra do Produto
Concluímos
A Derivada do Erro da
Última Camada
Calculemos o fator ao lado esquerdo do produto em
,
o erro
da saída, do único neurónio da última camada
.
Pela Regra da Cadeia,
Concluímos
Expressemos recursivamente as derivadas parciais das camadas
anteriores
,
… pelas posteriores; comecemos por expressar as de
pelas de
:
A Derivada do Erro da
Penúltima Camada
Para calcular
do neurónio
da penúltima camada
,
basta por
calcular
.
Para calcular o erro
do neurónio
da penúltima camada
,
observemos que
depende de
,
,
… Explicitamente,
Pela Regra da Cadeia
Os dois fatores, por definição
respetivamente derivação parcial de
,
são
logo
A Derivada do Erro
da Antepenúltima Camada
Para calcular
do neurónio
da antepenúltima camada
,
basta por
calcular
.
Para calcular o erro
do neurónio
da antepenúltima camada
,
observemos outra vez que
depende de
,
,
… Explicitamente,
Pela Regra da Cadeia
onde a última igualdade expande o
produto matricial do penúltimo termo. Os dois fatores de cada termo da
soma, por definição respetivamente derivação parcial de
,
são
logo
Por indução, vale esta equação para
cada neurónio
em qualquer camada
,
… no lugar de
.
6.10 Algoritmo Propagação para
Trás
O algoritmo da Propagação para Trás (=
Backpropagation) é um algoritmo para calcular eficientemente o
gradiente
pela Regra da Cadeia (de funções deriváveis). Em geral, fora do contexto
de uma rede neural, este algoritmo é conhecido como
auto-diferenciação inversa.
Seja
a função do neurónio
da camada
.
Lembremo-nos de que
para uma função de ativação
e uma função afim
.
O algoritmo da Propagação para Trás,
Calcula para cada entrada
os valores dos neurónios para a frente, isto é, dada a entrada
,
calcula
e
para todos os neurónios
das camadas ocultas
,
,
…,
e
calcula
e
para todos os neurónios da última camada
.
Calcula para cada entrada
as derivadas
dos neurónios para trás, isto é, calcula
o erro
da última camada,
os erros
,
,
… das camadas precedentes, e
as derivadas parciais
Calcula a derivada do erro da amostra inteira
Atualiza os pesos por
Observação. A computação das derivadas das funções de
ativação é usualmente fácil, por exemplo:
Se
,
então
,
e
se
,
então
.
7 Redes Recorrentes
Redes recorrentes são redes neurais artificiais que contêm ciclos
(direcionados). Fazem sucesso
no processamento de línguas naturais (= NLP = Natural Language
Processing), e
no aprendizado com reforço como no aprendizado dos jogos go e xadrez
(por AlphaGo e AlphaZero).
Redes recorrentes de Elman
Uma rede recorrenteUma rede recorrente
desdobrada
As matrizes ponderadas dos neurónios são
Pomos, no passo
,
onde
é, por exemplo, a ReLU ou tanh;
é, por exemplo, a função logística.
Comparação com Redes de
retropropagação
Uma rede recorrente não precisa de ter uma entrada e saída de
comprimento fixo, mas ambas podem variar. Esta restrição poderia ser
contornada por um tamanho máximo suficiente (da entrada e saída) e
preenchimento.
Tipos
Tipos diferentes
Retropropagação através do
tempo
Retropropagação numa rede recorrente
desdobrada
–> –> –> –> –> –> –> –> –>
7.2 Mapas Auto-Organizáveis
Um mapa auto-organizável é usado no aprendizado
não-supervisionado; isto é, para encontrar um espaço de rótulos
e aproximar a função divina
que rotula as entradas sem erros.
São dados
o espaço de entradas
,
e
uma amostra finita
incluso em
.
Como método, usamos como
espaço de hipóteses
todos os mapas auto-organizáveis: Um mapa auto-organizável
é
um número finito de neurónios enumerados por
,
…,
;
cada neurónio é
um vetor de pesos
em
,
e
uma posição
em
,
e
uma métrica (frequentemente chamada de topologia)
que mede a distância entre duas posições
e
;
é a composição de uma função de densidade probabilista unimodal, isto é,
que tem um único máximo, com a distância euclidiana; usualmente,
um quociente de aprendizado
em
.
A métrica e o quociente de aprendizado frequentemente são
parametrizados por um número de iteração tal que
e
(na norma de supremo) para
;
usualmente
,
e
para
e
positivos.
como algoritmo, atualizemos para cada exemplo
em
o vetor dos pesos
de cada neurónio por
onde
onde
é o (índice do) neurónio cujo vetor de pesos é
e
é o (índice do) neurónio cujo vetor de pesos minimize
entre os vetores de pesos
de todos os neurónios.
Exemplo
Sejam
,
…,
dados por
e
e
por
Seja
e
se, e tão-somente se,
.
Calculamos
e
Como
,
atualizamos
e obtemos
.
Calculemos novamente
Como
,
atualizamos
e obtemos
.
Calculemos novamente
Como
,
atualizamos
;
calculamos
Como
,
atualizamos
.
Referências
Bibliográficas
Abu-Mostafa, Yaser S, Malik Magdon-Ismail, e Hsuan-Tien Lin. 2012.
Learning from data. Vol. 4. AMLBook New York, NY, USA.
Telgarsky, Matus. 2016. «Benefits of depth in neural
networks». Em Conference on learning theory, 1517–39.
PMLR. https://arxiv.org/abs/1602.04485.